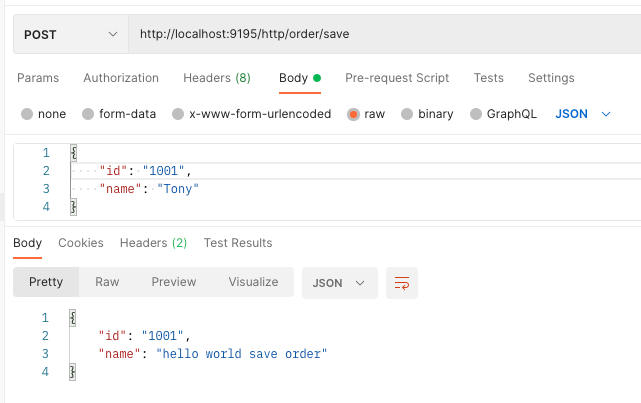
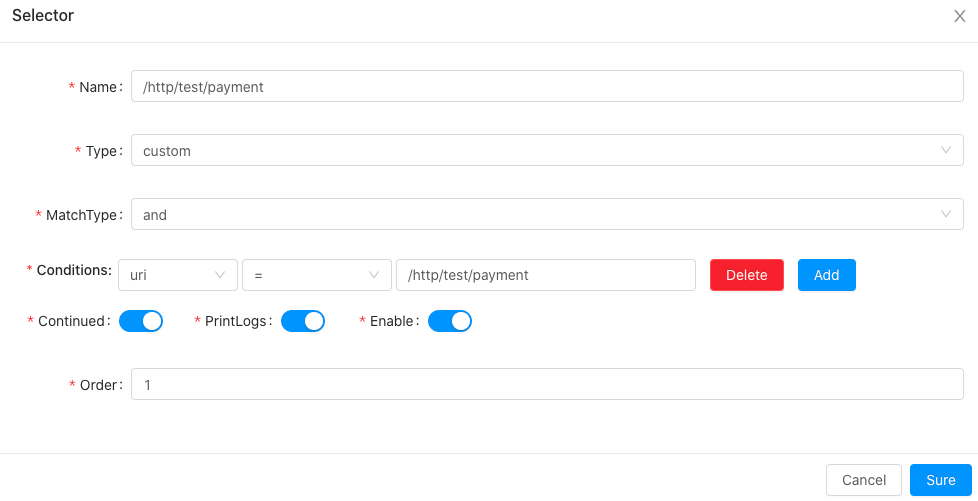
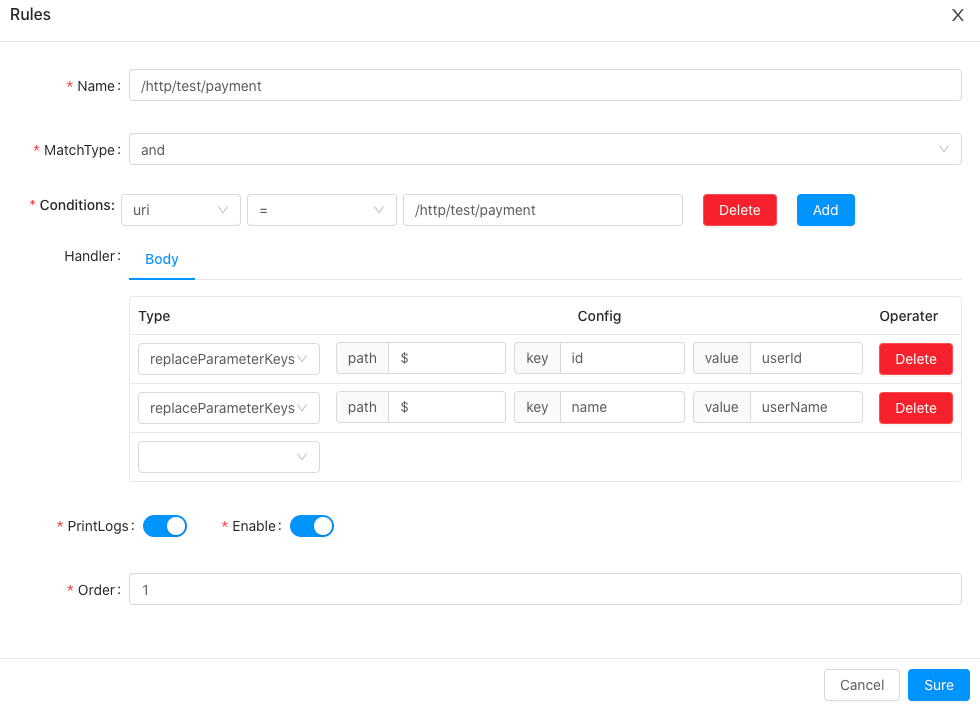
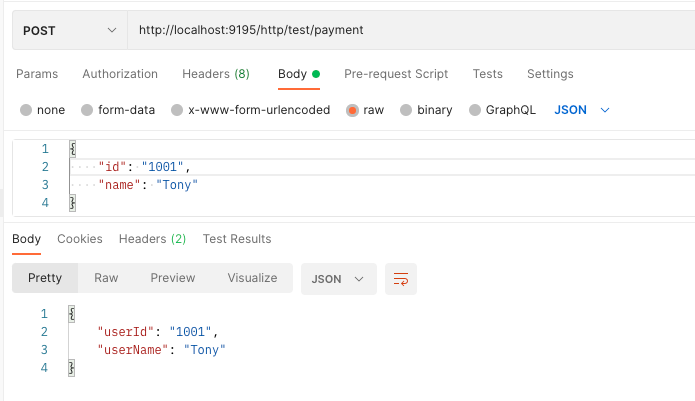
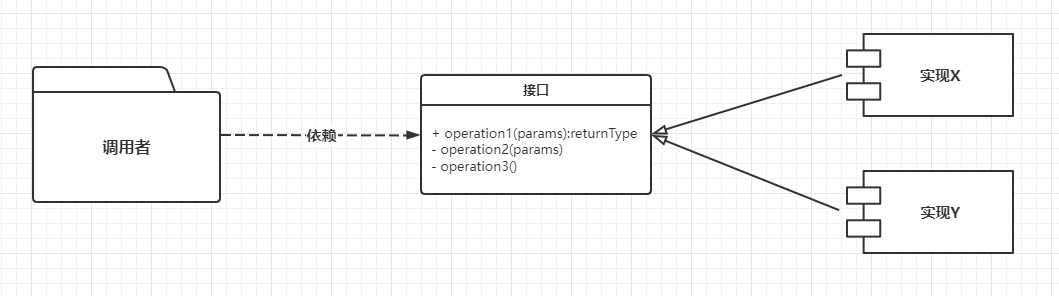
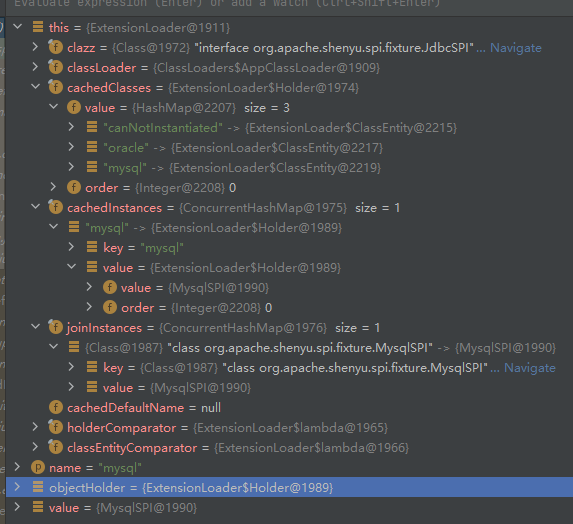
private Map<String, ClassEntity> getExtensionClassesEntity() {
Map<String, ClassEntity> classes = cachedClasses.getValue();
if (Objects.isNull(classes)) {
synchronized (cachedClasses) {
classes = cachedClasses.getValue();
if (Objects.isNull(classes)) {
classes = loadExtensionClass();
cachedClasses.setValue(classes);
cachedClasses.setOrder(0);
}
}
}
return classes;
}
private Map<String, ClassEntity> loadExtensionClass() {
SPI annotation = clazz.getAnnotation(SPI.class);
if (Objects.nonNull(annotation)) {
String value = annotation.value();
if (StringUtils.isNotBlank(value)) {
cachedDefaultName = value;
}
}
Map<String, ClassEntity> classes = new HashMap<>(16);
loadDirectory(classes);
return classes;
}
private void loadDirectory(final Map<String, ClassEntity> classes) {
String fileName = SHENYU_DIRECTORY + clazz.getName();
try {
Enumeration<URL> urls = Objects.nonNull(this.classLoader) ? classLoader.getResources(fileName)
: ClassLoader.getSystemResources(fileName);
if (Objects.nonNull(urls)) {
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
loadResources(classes, url);
}
}
} catch (IOException t) {
LOG.error("load extension class error {}", fileName, t);
}
}
private void loadResources(final Map<String, ClassEntity> classes, final URL url) throws IOException {
try (InputStream inputStream = url.openStream()) {
Properties properties = new Properties();
properties.load(inputStream);
properties.forEach((k, v) -> {
String name = (String) k;
String classPath = (String) v;
if (StringUtils.isNotBlank(name) && StringUtils.isNotBlank(classPath)) {
try {
loadClass(classes, name, classPath);
} catch (ClassNotFoundException e) {
throw new IllegalStateException("load extension resources error", e);
}
}
});
} catch (IOException e) {
throw new IllegalStateException("load extension resources error", e);
}
}
private void loadClass(final Map<String, ClassEntity> classes,
final String name, final String classPath) throws ClassNotFoundException {
Class<?> subClass = Objects.nonNull(this.classLoader) ? Class.forName(classPath, true, this.classLoader) : Class.forName(classPath);
if (!clazz.isAssignableFrom(subClass)) {
throw new IllegalStateException("load extension resources error," + subClass + " subtype is not of " + clazz);
}
if (!subClass.isAnnotationPresent(Join.class)) {
throw new IllegalStateException("load extension resources error," + subClass + " without @" + Join.class + " annotation");
}
ClassEntity oldClassEntity = classes.get(name);
if (Objects.isNull(oldClassEntity)) {
Join joinAnnotation = subClass.getAnnotation(Join.class);
ClassEntity classEntity = new ClassEntity(name, joinAnnotation.order(), subClass);
classes.put(name, classEntity);
} else if (!Objects.equals(oldClassEntity.getClazz(), subClass)) {
throw new IllegalStateException("load extension resources error,Duplicate class " + clazz.getName() + " name "
+ name + " on " + oldClassEntity.getClazz().getName() + " or " + subClass.getName());
}
}