RateLimiter SPI 代码分析
限流是网关必备的功能,用来应对高并发请求的场景。当系统受到异常攻击,短期内聚集了大量的流量;当有大量低级别的请求,处理这些请求会影响关键业务的处理,需要限制这些请求的访问速度; 或者系统内部出现一些异常,不能满负荷的服务整个应用请求等等。这些情况下,都需要启用限流来保护系统。可以拒绝服务、等待或降级处理,将流量限制到系统可接受的量,或者只允许某些域名(或某些业务)的请求优先处理。
针对以上的场景需求,在设计一个API网关的限流功能时,就需要考虑如下的扩展点:
- 可以支持多种限流的算法,并易于扩展。
- 要可以支持多种限流的方式,能区分用户群、高低优先级的请求。
- 要支持高并发,能快速的做出限制或通过的决策。
- 要有容错处理,如果限流程序出错,网关系统能继续执行。
本文会先介绍shenyu网关限流部分的总体技术架构,之后重点分析RateLimiter SPI扩展实现的代码。
This article based on
shenyu-2.4.0version of the source code analysis.
RateLimiter 总体设计说明
WebFlux是Spring 提供的基于Reactor模型的异步非阻塞框架,能提升吞吐量,使系统有更好的可伸缩性。Apache Shenyu网关的插件功能基于WebFlux框架实现的。RateLimiter功能是在ratelimiter-plugin中实现。在限流过程中,常用的算法有令牌桶、漏桶等算法,这些算法执行中,需要检核请求的来源,对已使用的流量做计数及逻辑计算,判定是否允许通过。为了提高并发及性能, 将计数和算法逻辑处理,都放到redis中。Java代码负责做数据参数的传递。在调用redis时,lua脚本可以常驻在redis内存中,能减少网络开销,并可以作为一个整体执行,具有原子性。Spring Data Redis 提供了对redis命令执行的抽象,执行序列化,及自动使用redis 脚本缓存。在这个plugin中,由于采用了reactor 非阻塞框架,所以采用Spring Redis Reactive类库实现对redis的功能调用。
这个plugin中的类包图如下,重点标出了与RateLimiter SPI相关的两个package: resolver 和algorithm.
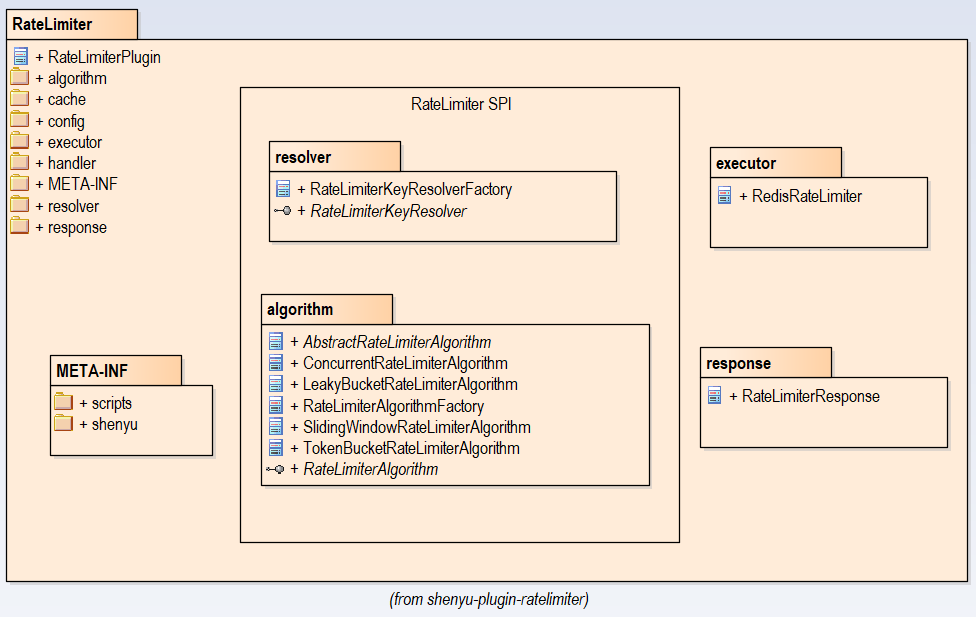
RateLimiter SPI的设计
由于采用了Spring data+ Redis +lua架构实现了高并发的需求。 如何做到对算法和限流方式的扩展呢? Shenyu ratelimiter plugin中设计了两个SPI来实现这两个需求:
RateLimiterAlgorithm:用来扩展不同的限流算法。RateLimiterKeyResolver: 用于扩展获取请求的关键信息,用于区分流量,例如按IP 地址、按某一段域名等来区分访问的请求。
SPI的具体实作类与配置信息位于:SHENYU_DIRECTORY目录下 (默认在/META-INF/shenyu)下。
RateLimiterKeyResolver
获取请求的关键信息,用于分组限流,例如按URL/ 用户 / IP 等, RateLimiterKeyResolver 接口定义如下:
@SPI
public interface RateLimiterKeyResolver {
/**
* get Key resolver's name.
*
* @return Key resolver's name
*/
String getKeyResolverName();
/**
* resolve.
*
* @param exchange exchange the current server exchange {@linkplain ServerWebExchange}
* @return rate limiter key
*/
String resolve(ServerWebExchange exchange);
}
@SPI将当前interface 注册为Shenyu SPI 接口。resolve(ServerWebExchange exchange)方法用来提供解析方式。
RateLimiterKeyResolver SPI 提供了两种key resolver, WholeKeyResolve和 RemoteAddrKeyResolver,其中RemoteAddrKeyResolver中的resolve方法代码如下:
@Override
public String resolve(final ServerWebExchange exchange) {
return Objects.requireNonNull(exchange.getRequest().getRemoteAddress()).getAddress().getHostAddress();
}
其key值为请求的IP地址。 基于SPI及工厂类的实现,可以非常方便的扩展实现新的key resolver,如URL,用户等等。
RateLimiterAlgorithm SPI
RateLimiterAlgorithm SPI 用来实现对不同限流算法的识别、加载和定义,其类图如下:
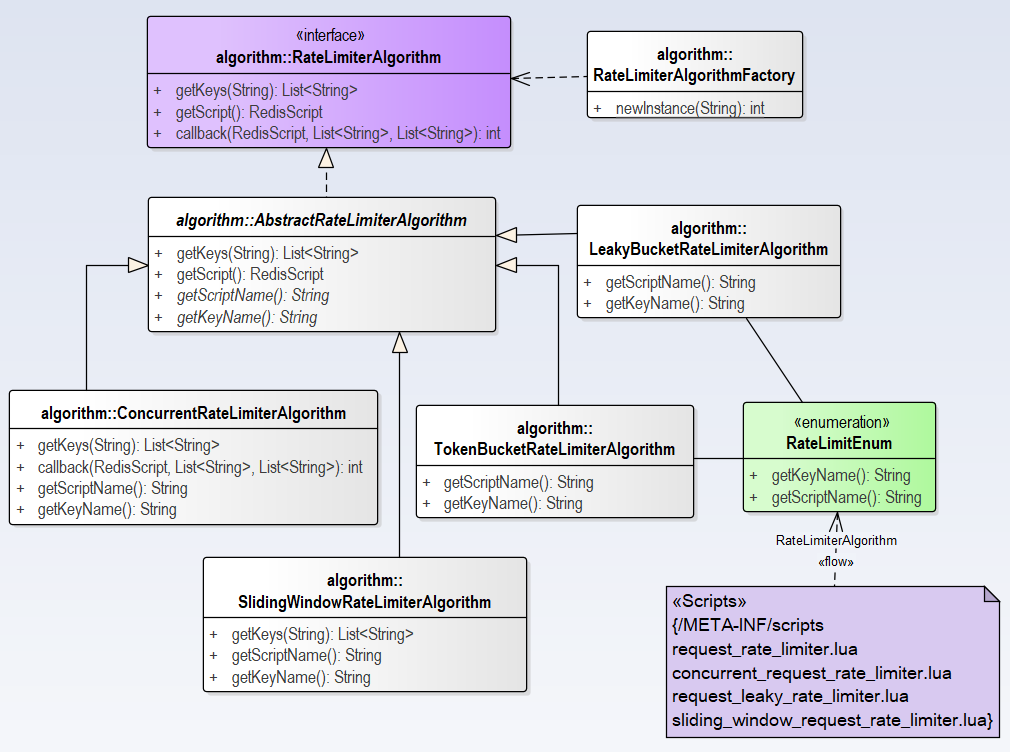
本模组使用了工厂模式,提供了接口类、抽象类和工厂类,提供了4个实现类,其中实现类对应的Lua脚本在 RateLimitEnum 中做了定义,放置在 /META-INF/scripts 目录下。接口RateLimiterAlgorithm的代码如下:
@SPI
public interface RateLimiterAlgorithm<T> {
RedisScript<T> getScript();
List<String> getKeys(String id);
/**
* Callback string.
*
* @param script the script
* @param keys the keys
* @param scriptArgs the script args
*/
default void callback(final RedisScript<?> script, final List<String> keys, final List<String> scriptArgs) {
}
}
@SPI 将这个接口注册为shenyu SPI, 其中定义了三个方法:
getScript()方法返回一个RedisScript对象,这个对象将传递给Redis。getKeys(String id)返回一个键值的List.callback()回调函��数用于异步处理一些需要在返回后做的处理,缺省是空方法。
抽象类 AbstractRateLimiterAlgorithm
在这个类中,实现了接口的模板方法,使用参数类型为List<Long>, 抽象方法getScriptName() 和getKeyName() 留给各个实作类来实现。如下的getScript() 是这个类中读取lua脚本的处理代码。
public RedisScript<List<Long>> getScript() {
if (!this.initialized.get()) {
DefaultRedisScript redisScript = new DefaultRedisScript<>();
String scriptPath = "/META-INF/scripts/" + getScriptName();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(scriptPath)));
redisScript.setResultType(List.class);
this.script = redisScript;
initialized.compareAndSet(false, true);
return redisScript;
}
return script;
}
AtomicBoolean类型的变量initialized 用来标记lua脚本是否有被加载。 如果还没有加载,就从/META-INF/scripts/目录下,读取scriptName指定的Lua文件,加载成RedisScript对象。指定结果为List类型, 设定量initialized为true,避免重复加载。 返回 RedisScript对象。
AbstractRateLimiterAlgorithm中getKeys()的代码如下,
@Override
public List<String> getKeys(final String id) {
String prefix = getKeyName() + ".{" + id;
String tokenKey = prefix + "}.tokens";
String timestampKey = prefix + "}.timestamp";
return Arrays.asList(tokenKey, timestampKey);
}
这个模板方法中,产生了两个字符串,其中,tokenKey会作为Key传递给redis, 指向一个有序集合。 timestampKey是一个以传入id 为识别的字符串。
可以从上面的类图中看到,ConcurrentRateLimiterAlgorithm 和SlidingWindowRateLimiterAlgorithm 有覆写getKeys(String id)方法,而两外两个算法程序,则采用的是抽象类中的实现。也只有 ConcurrentRateLimiterAlgorithm 重写了callback()方法。下文中我们会对此做进一步的分析。
工厂类RateLimiterAlgorithmFactory
RateLimiterAlgorithmFactory 中依据算法名称,获取RateLimiterAlgorithm实例的方法代码如下:
public static RateLimiterAlgorithm<?> newInstance(final String name) {
return Optional.ofNullable(ExtensionLoader.getExtensionLoader(RateLimiterAlgorithm.class).getJoin(name)).orElse(new TokenBucketRateLimiterAlgorithm());
}
按照Apache shenyu SPI的规则,由加载器ExtensionLoader获得实作类,当找不到算法时,默认返回令牌桶算法实现类。
与Redis做资料交互
从上面代码我们了解到Apache Shenyu网关中,RateLimiter SPI 的基本扩展点,在Shenyu网关运行中,应用ReactiveRedisTemplate 来异步执行对redis的调用处理。实现代码在RedisRateLimiter类的isAllowed()方法中,其部分代码如下:
public Mono<RateLimiterResponse> isAllowed(final String id, final RateLimiterHandle limiterHandle) {
// get parameters that will pass to redis from RateLimiterHandle Object
double replenishRate = limiterHandle.getReplenishRate();
double burstCapacity = limiterHandle.getBurstCapacity();
double requestCount = limiterHandle.getRequestCount();
// get the current used RateLimiterAlgorithm
RateLimiterAlgorithm<?> rateLimiterAlgorithm = RateLimiterAlgorithmFactory.newInstance(limiterHandle.getAlgorithmName());
........
Flux<List<Long>> resultFlux = Singleton.INST.get(ReactiveRedisTemplate.class).execute(script, keys, scriptArgs);
return resultFlux.onErrorResume(throwable -> Flux.just(Arrays.asList(1L, -1L)))
.reduce(new ArrayList<Long>(), (longs, l) -> {
longs.addAll(l);
return longs;
}).map(results -> {
boolean allowed = results.get(0) == 1L;
Long tokensLeft = results.get(1);
return new RateLimiterResponse(allowed, tokensLeft);
})
.doOnError(throwable -> log.error("Error occurred while judging if user is allowed by RedisRateLimiter:{}", throwable.getMessage()))
.doFinally(signalType -> rateLimiterAlgorithm.callback(script, keys, scriptArgs));
}
POJO 对象RateLimiterHandle 中,定义了限流所需的属性算法名称, 速录,容量,请求的数量 。首先 从limiterHandle 包装类中取得需要传入redis的几个参数。之后从RateLimiterAlgorithmFactory 从工厂类取得当前配置的限流算法。 之后做Key值和参数的传递。
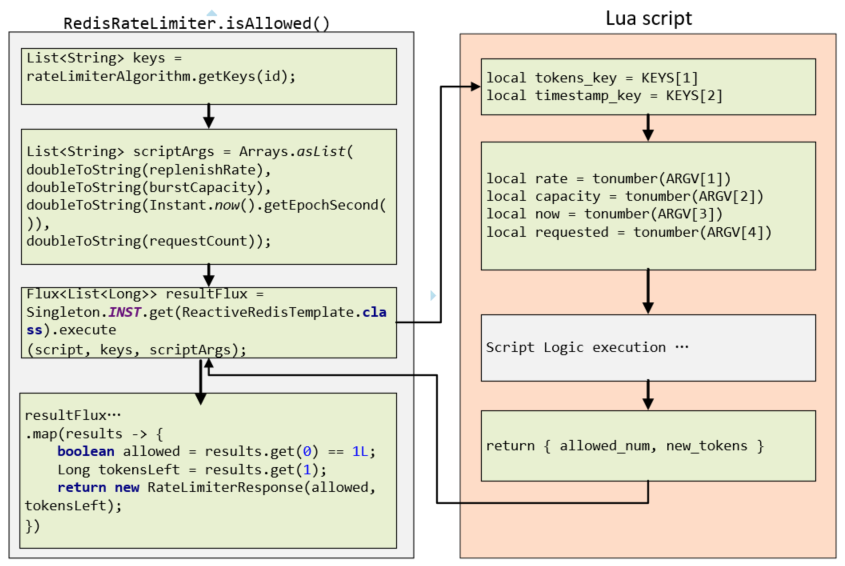
为了更方便阅读,下图给出了java代码与redis执行参数输入、输出的传递过程。左边是isAllowed() 函数的后半部分代码,右边是一个Lua脚本的输入输出代码。
下面说明Java代码的执行过程:
-
从
getKeys()方法获得两个键值List<String>. 其中第一个Key会映射为Redis中的有序集合。 -
设定4个参数:速率 replenishRate ,容量 burstCapacity, 时间戳, 返回当前java 纪元秒数(长整数)EpochSecond, 请求的数量 requestcount.
-
按所设定的脚本、Key值、参数调用
ReactiveRedisTemplate功能,执行redis处理。返回参数是Flux<List<Long>>类型 -
通过reduce方法将其返回值从
Flux<ArrayList<Long>>类型转换为Mono<ArrayList<Long>>,再经过map方法,转换为Mono<RateLimiterResponse>返回。返回结果有两个资料,allowed =1, 代表允许通过,0-不通过;而第二个返回参数tokensLeft,是可用的剩余请求数量。
5.容错性方面,由于使用的是reactor 的非阻塞通讯模型,当发生错误时,会执行onErrorResume()语句,Flux.just产生返回资料, 默认为allowed=1, 代表允许通过, 并丢出错误日志。
6.之后执行doFinally()方法,执行算法实现类的callback方法。
4种限流算法
上面我们了解了网关中如何通过Java代码如何与Redis 做通讯,这一节我们通过简要分析网关中提供的4种限流算法中的一些代码,来理解如何开发使用RateLimiter SPI的接口方法,并与Redis有效协作。
Ratelimiter SPI目前提供了4种限流算法:
| Algorithm name | Java class | Lua script file |
|---|---|---|
| Request rate limiter | TokenBucketRateLimiterAlgorithm | request_rate_limiter.lua |
| Slide window rate limiter | SlidingWindowRateLimiterAlgorithm | liding_window_request_rate_limiter.lua |
| Concurrent rate limiter | ConcurrentRateLimiterAlgorithm | concurrent_request_rate_limiter.lua |
| Leaky bucket algorithm | LeakyBucketRateLimiterAlgorithm | request_leaky_rate_limiter.lua |
- 令牌桶限流:按请求数量限流,设置每秒N个请求,超过N的请求会拒绝服务。算法实现时,以时间间隔计算匀速产生令牌的数量。若每次请求的数量,小于桶内令牌的数量,则允许通过。 时间窗口为 2*容积/速率。
- 滑动窗口限流:与令牌桶限流不同在于,其窗口大小比令牌桶的窗口小,为一个容积/速率。并且每次移动向后一个时间时间窗口。其他限流原理与令牌桶类似。
- 并发的请求速率限流:严格限制并发访问量为N个请求,大于N的请求会被拒绝。每次当有新请求,查看计数是否大于N, 若小于N则允许通过,计数加1。 当这个请求调用结束时,会释放这个信号(计数减1)
- 漏桶算法: 相对于令牌桶算法,漏桶算法有助于减少流量聚集,实现更为平滑的限流处理。 漏桶算法强制以常数N的速率输出流量,其以漏桶为模型,可漏水的量为时间间隔 *速率。若可漏水量>已使用量,则已使用量设为0( 清空漏桶),否则已使用量要减去可漏水量。 若请求数量+ 已使用量< 总容量,则允许请求通过。
下面以 并行限流算法为例,解读Lua和Java代码,查看callback 方法的使用。 通过解读令牌桶和滑动窗口算法代码,了解getKey()方法的使用。
并发请求数限流中使用callback方法
首先ConcurrentRateLimiterAlgorithm 的getKeys() 方法覆写了抽象类中的模板方法:
@Override
public List<String> getKeys(final String id) {
String tokenKey = getKeyName() + ".{" + id + "}.tokens";
String requestKey = UUIDUtils.getInstance().generateShortUuid();
return Arrays.asList(tokenKey, requestKey);
}
第二个元素 requestKey 是一个long型不重复值(由一个分布式ID产生器产生的,递增,比当前时间EpochSecond小), 相应的concurrent_request_rate_limiter.lua的代码:
local key = KEYS[1]
local capacity = tonumber(ARGV[2])
local timestamp = tonumber(ARGV[3])
local id = KEYS[2]
这里id 即是取得上面的getKeys()方法产生的requestKey, 一个uuid. 后续的处理如下:
local count = redis.call("zcard", key)
local allowed = 0
if count < capacity then
redis.call("zadd", key, timestamp, id)
allowed = 1
count = count + 1
end
return { allowed, count }
先用zcard命令统计redis中key值所对应的有序集合中的元素个数,若元素总数count小于容量,则允许通过,并用zadd key score member方法,向key所在的有序集合中,添加一个元素id, 其score为timestamp. 则此时元素的总个数count实际为count+1.
以上的代码都是在redis中作为一个原子操作来执行的。当同一个key (例如Ip下)有大量并发请求时,redis记录的该ip的有序集合的数量count也在不断累加中。当超过容量限制,则会拒绝服务。
并发请求数限流算法中,要求当请求调用结束时,要释放这个信号量,lua代码中并没有做这个处理。
我们来看看 ConcurrentRateLimiterAlgorithm类中的回调函数:
@Override
@SuppressWarnings("unchecked")
public void callback(final RedisScript<?> script, final List<String> keys, final List<String> scriptArgs) {
Singleton.INST.get(ReactiveRedisTemplate.class).opsForZSet().remove(keys.get(0), keys.get(1)).subscribe();
}
这里做了一个异步的订阅处理,通过ReactiveRedisTemplate删除redis中(key, id)的元素,等待调用结束后,释放这个信号。这个remove的处理不能放到lua脚本中执行,否则逻辑就是错误的。这也正是RateLimiterAlgorithm SPI 设计callback方法的用意。
令牌桶算法中使用getKeys()
对应的Lua 代码如下:
local tokens_key = KEYS[1]
local timestamp_key = KEYS[2]
省略获取参数的代码
local fill_time = capacity/rate
local ttl = math.floor(fill_time*2)
时间窗口ttl 大概是 2* 容量/速率.
local last_tokens = tonumber(redis.call("get", tokens_key))
if last_tokens == nil then
last_tokens = capacity
end
从有序集合中取得上次使用的token,如果没有则last_tokens = 容量。
local last_refreshed = tonumber(redis.call("get", timestamp_key))
if last_refreshed == nil then
last_refreshed = 0
end
以timestamp_key为key,从有序集合中取得上次刷新时间,默认为0.
local delta = math.max(0, now-last_refreshed)
local filled_tokens = math.min(capacity, last_tokens+(delta*rate))
local allowed = filled_tokens >= requested
local allowed_num = 0
if allowed then
new_tokens = filled_tokens - requested
allowed_num = 1
end
时间间隔*速率匀速产生令牌,若令牌数量>请求数量,则allowed=1, 并且更新令牌数量。
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
return { allowed_num, new_tokens }
这里now是传入的当前时间(EpochSecond),设置tokens_key所对应的有序集合的值为 new_tokens(即新令牌数量) , 过期时间为ttl。 更新集合中,timestamp_key的值为当前时间,过期时间为ttl.
滑动窗口算法中使用getKeys方法
在SlidingWindowRateLimiterAlgorithm 的getKeys()同样覆写了父类,代码与ConcurrentRateLimiterAlgorithm 方法代码一致。
如下为滑动窗口算法的Lua代码,省略了其他参数的接收代码。
local timestamp_key = KEYS[2]
......
local window_size = tonumber(capacity / rate)
local window_time = 1
设定窗口大小为容积/速率。
local last_requested = 0
local exists_key = redis.call('exists', tokens_key)
if (exists_key == 1) then
last_requested = redis.call('zcard', tokens_key)
end
获取当前key 的基数
local remain_request = capacity - last_requested
local allowed_num = 0
if (last_requested < capacity) then
allowed_num = 1
redis.call('zadd', tokens_key, now, timestamp_key)
end
计算剩余可用量 = 容量 减去已使用量,若last_requested < capacity ,则允许通过,并且在tokens_key为key的有序集合中,增加一个 元素(key =timestam_key,value= now)
redis.call('zremrangebyscore', tokens_key, 0, now - window_size / window_time)
redis.call('expire', tokens_key, window_size)
return { allowed_num, remain_request }
前面已经设定window_time=1, 用Redis的 zremrangebyscore命令,移除有序集合中,score为[0- 当前时间-窗口大小]的元素,即移动一个窗口大小。设定tokens_key的过期时间为窗口大小。
在AbstractRateLimiterAlgorithm的模板方法中,getKeys(final String id) 给出的第二个值(以secondKey指代),是拼接了{id} (即resolve key)的一个固定字符串。从上面三个算法代码可以看到,在令牌桶算法中,secondKey在Lua代码执行中会更新为最新的时间,所以无所谓传入的值。而在并发限流算法中,会以此secondKey为条件,在java callback方法中移除对应的元素。而在滑动窗口算法中,这个secondKey的�值,会作为一个新元素的key, 增加到当前有序集合中,并在做窗口滑动中,过期的资料会被删除掉。
总之,当设计新的限流算法时,要根据算法需要仔细设计getKey()方法。
如何调用 RateLimiter SPI
在RateLimiter Plug中的doExecute()方法中,传入的三个参数 exchange 为请求的连接, chain 为shenyu插件的调用链,selector 是选择器,rule是系统中配置的规则参数资料。
protected Mono<Void> doExecute(final ServerWebExchange exchange, final ShenyuPluginChain chain, final SelectorData selector, final RuleData rule) {
RateLimiterHandle limiterHandle = RatelimiterRuleHandleCache.getInstance()
.obtainHandle(CacheKeyUtils.INST.getKey(rule));
String resolverKey = Optional.ofNullable(limiterHandle.getKeyResolverName())
.flatMap(name -> Optional.of("-" + RateLimiterKeyResolverFactory.newInstance(name).resolve(exchange)))
.orElse("");
return redisRateLimiter.isAllowed(rule.getId() + resolverKey, limiterHandle)
.flatMap(response -> {
if (!response.isAllowed()) {
exchange.getResponse().setStatusCode(HttpStatus.TOO_MANY_REQUESTS);
Object error = ShenyuResultWrap.error(ShenyuResultEnum.TOO_MANY_REQUESTS.getCode(), ShenyuResultEnum.TOO_MANY_REQUESTS.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
return chain.execute(exchange);
});
}
1.首先,从缓存中,取得系统设定的限流参数RateLimiterHandle实例 limiterHandle.
2.根据name指定的Resolver 获得请求的连接Key信息(如地址等).
3.调用 RedisRateLimiter的 isAllowed方法, 获取返回值后,
4.若isAllowd=false,做错误处理
5.如果 isAllowed=true,return chain.execute(exchange), 对该请求做后续处理,传递到调用链的下一关。
Summary
整个RateLimiter plugin框架基于Spring WebFlux开发,用redis 和lua脚本做限流计数及核心逻辑处理,支持高并发及弹性扩展。
-
RateLimiterSPI提供了两个SPI接口,通过应用面向接口设计及各种设计模式,可以方便的增加新的限流算法,以及各种流量解析规则。 -
提供了令牌桶、并发速率限流、滑动窗口、漏桶4种限流算法。在设计算法实现时,需要根据算法特征设计KEY值,用Lua脚本实现在redis中要处理的逻辑,设计
callback()方法做后续的数据处理。 -
响应式编程,实现过程简洁高效。