1. Overview
1.1 Plugin Name
- Logging-Kafka Plugin
1.2 Appropriate Scenario
- collect http request log to Kafka, consume Kafka message to another application and analysis.
1.3 Plugin functionality
Apache ShenYuThe gateway receives requests from the client, forwards them to the server, and returns the server results to the client. The gateway can record the details of each request,
The list includes: request time, request parameters, request path, response result, response status code, time consumption, upstream IP, exception information waiting.
The Logging-Kafka plugin is a plugin that records access logs and sends them to the Kafka cluster.
1.4 Plugin code
-
Core Module
shenyu-plugin-logging-kafka. -
Core Class
org.apache.shenyu.plugin.logging.kafka.LoggingKafkaPlugin -
Core Claas
org.apache.shenyu.plugin.logging.kafka.client.KafkaLogCollectClient
1.5 Added Since Which shenyu version
- Since ShenYu 2.5.0
1.6 Technical Solutions
- Architecture Diagram
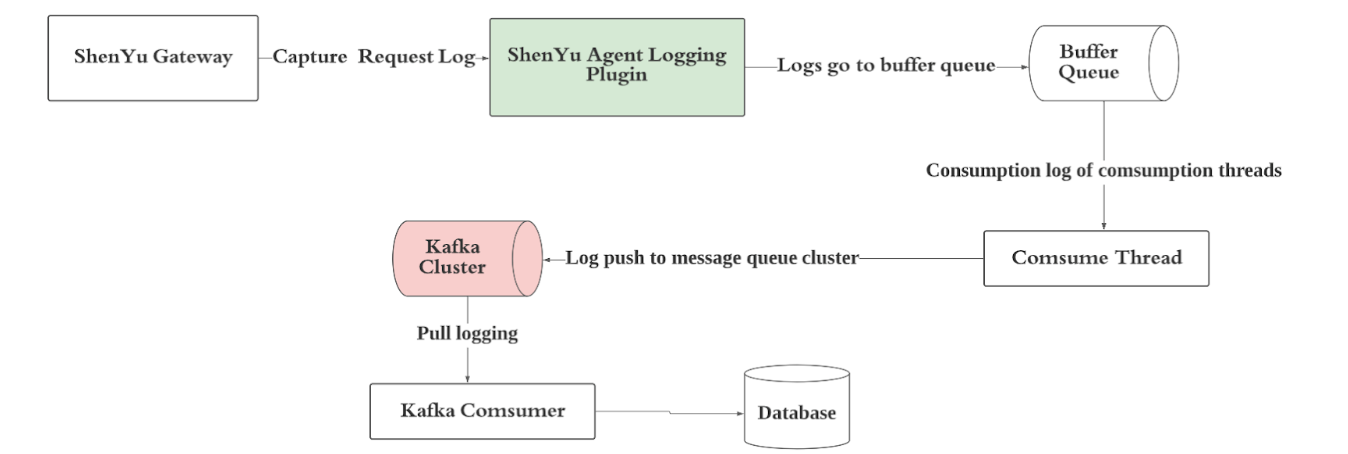
-
Full asynchronous collection and delivery of
Logginginside theApache ShenYugateway -
Logging platform by consuming the logs in the
Kafkacluster for repository, and then usingGrafana,Kibanaor other visualization platform to display
2. How to use plugin
2.1 Plugin-use procedure chart
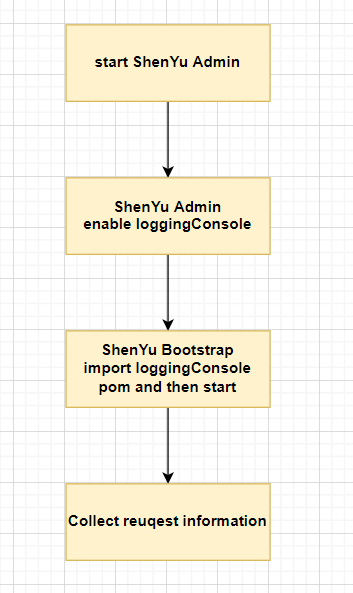
2.2 Import pom
- Add the
Logging-Kafkadependency to the gateway'spom.xmlfile.
<!--shenyu logging-kafka plugin start-->
<dependency>
<groupId>org.apache.shenyu</groupId>
<artifactId>shenyu-spring-boot-starter-plugin-logging-kafka</artifactId>
<version>${project.version}</version>
</dependency>
<!--shenyu logging-kafka plugin end-->
2.3 Enable plugin
- In
shenyu-admin--> Basic Configuration --> Plugin Management -->loggingKafka, configure the kafka parameter and set it to on.
2.4 Config plugin
2.4.1 Open the plugin and configure kafka, configure it as follows.
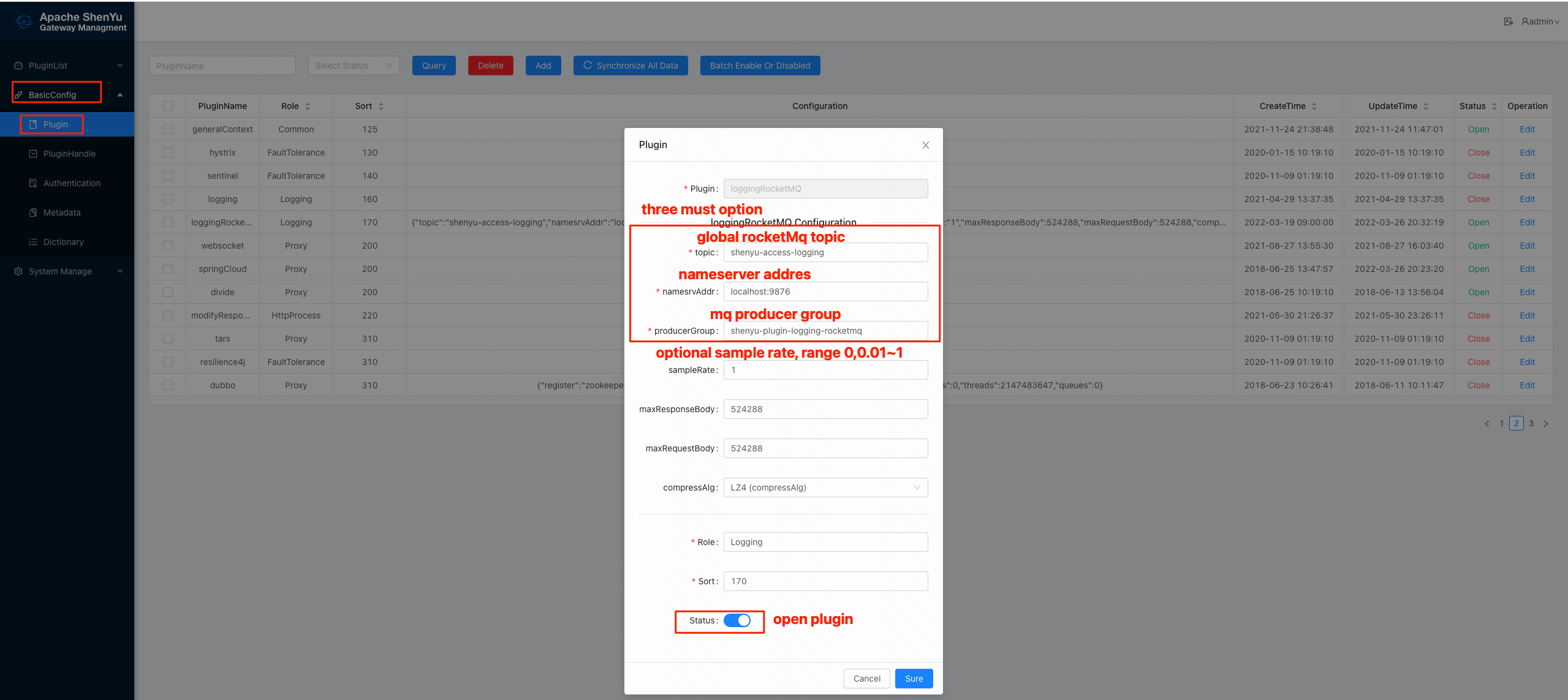
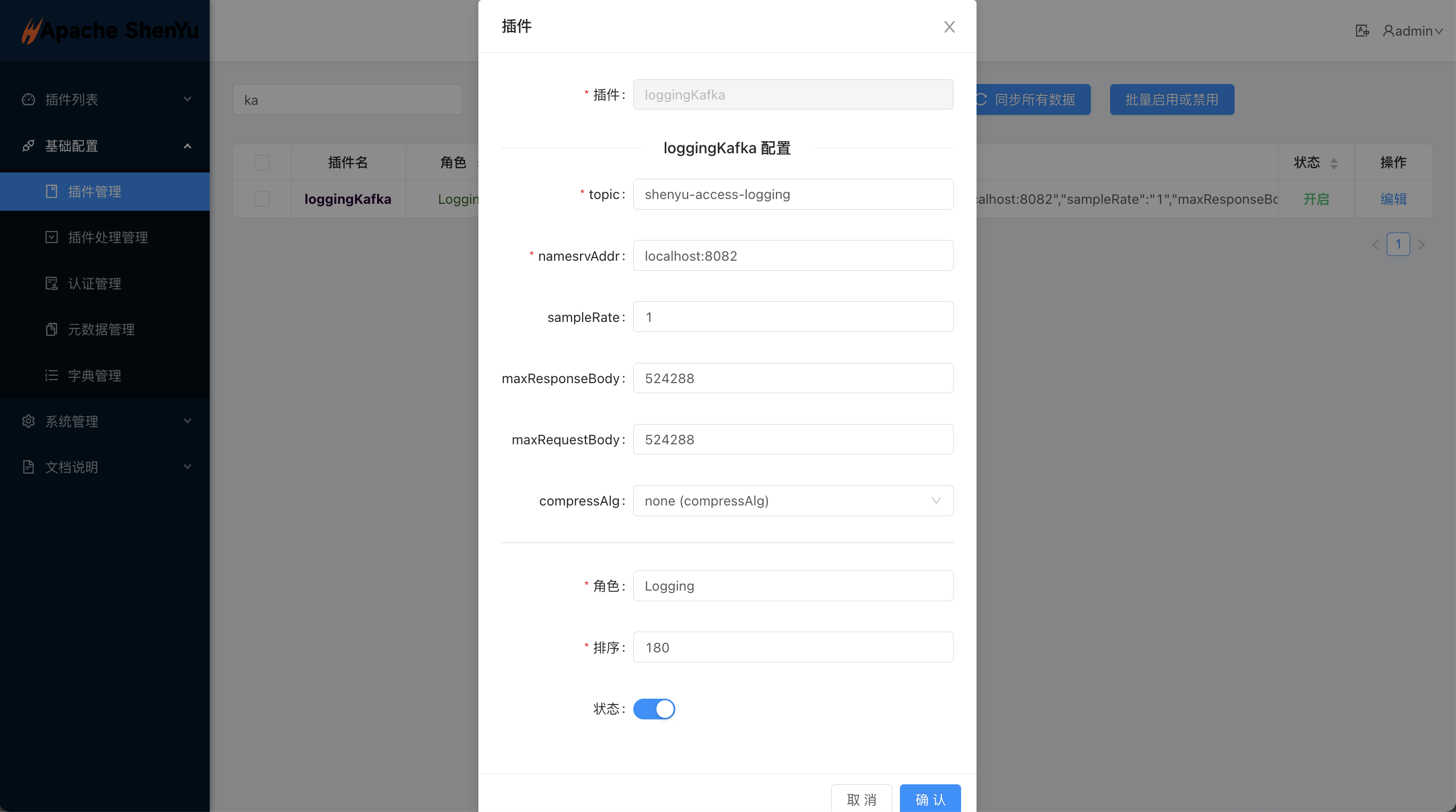
- The individual configuration items are described as follows:
| config-item | type | description | remarks |
| topic | String | Message Queue Topics | must |
| namesrvAddr | String | Message queue nameserver address | must |
| sampleRate | String | Sampling rate, range 0~1, 0: off, 0.01: acquisition 1%, 1: acquisition 100% | Optional, default 1, all collection |
| compressAlg | String | Compression algorithm, no compression by default, currently supports LZ4 compression | Optional, no compression by default |
| maxResponseBody | Ingeter | Maximum response size, above the threshold no response will be collected | Optional, default 512KB |
| maxRequestBody | Ingeter | Maximum request body size, above the threshold no request body will be collected | Optional, default 512KB |
| Except for topic, namesrvAddr, all others are optional, in most cases only these 3 items need to be configured. The default group id is "shenyu-access-logging" |
2.4.2 Configuring Selectors and Rulers
- For detailed configuration of selectors and rules, please refer to: Selector and rule management。
In addition, sometimes a large gateway cluster corresponds to multiple applications (business), different applications (business) corresponds to different topics, related to isolation,
then you can configure different topics (optional) and sampling rate (optional) by selector, the meaning of the configuration items as shown in the table above.
The operation is shown below:
2.5 Logging Info
collect request info as follows
| Field Name | Meaning | Description | Remarks |
|---|---|---|---|
| clientIp | Client IP | ||
| timeLocal | Request time string, format: yyyy-MM-dd HH:mm:ss.SSS | ||
| method | request method (different rpc type is not the same, http class for: get, post wait, rpc class for the interface name) | ||
| requestHeader | Request header (json format) | ||
| responseHeader | Response header (json format) | ||
| queryParams | Request query parameters | ||
| requestBody | Request Body (body of binary type will not be captured) | ||
| requestUri | Request uri | ||
| responseBody | Response body | ||
| responseContentLength | Response body size | ||
| rpcType | rpc type | ||
| status | response status | ||
| upstreamIp | Upstream (program providing the service) IP | ||
| upstreamResponseTime | Time taken by the upstream (program providing the service) to respond to the request (ms ms) | ||
| userAgent | Requested user agent | ||
| host | The requested host | ||
| module | Requested modules | ||
| path | The requested path | ||
| traceId | Requested Link Tracking ID | Need to access link tracking plugins, such as skywalking,zipkin |
2.6 Examples
2.6.1 Collect Http Log by Kafka
2.6.1.1 Plugin Configuration
Open the plugin and configure kafka, configure it as follows.
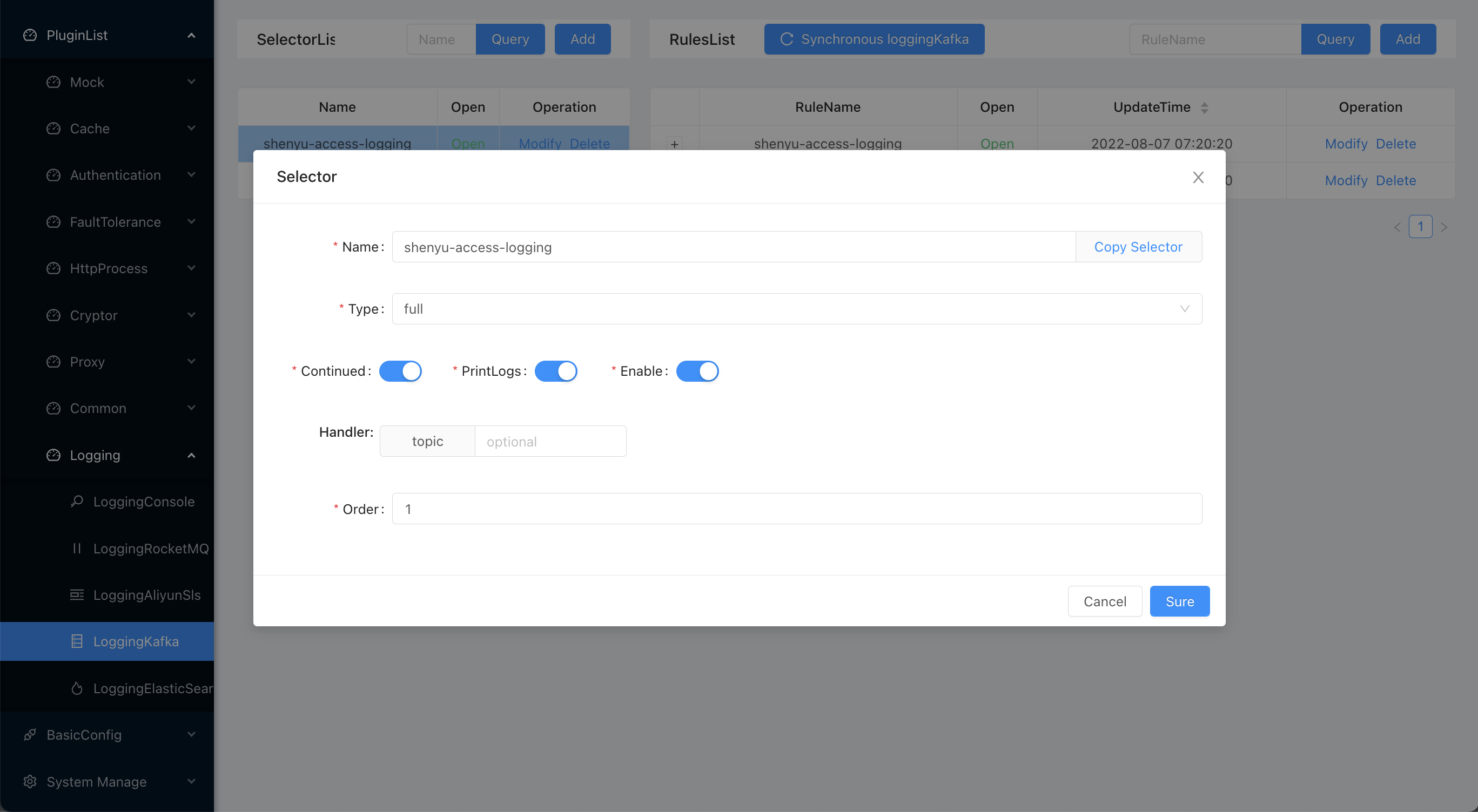
2.6.1.2 Selector Configuration
For detailed configuration of selectors and rules, please refer to: Selector and rule management。
In addition, sometimes a large gateway cluster corresponds to multiple applications (business), different applications (business) corresponds to different topics, related to isolation,
then you can configure different topics (optional) and sampling rate (optional) by selector, the meaning of the configuration items as shown in the table above.
The operation is shown below:
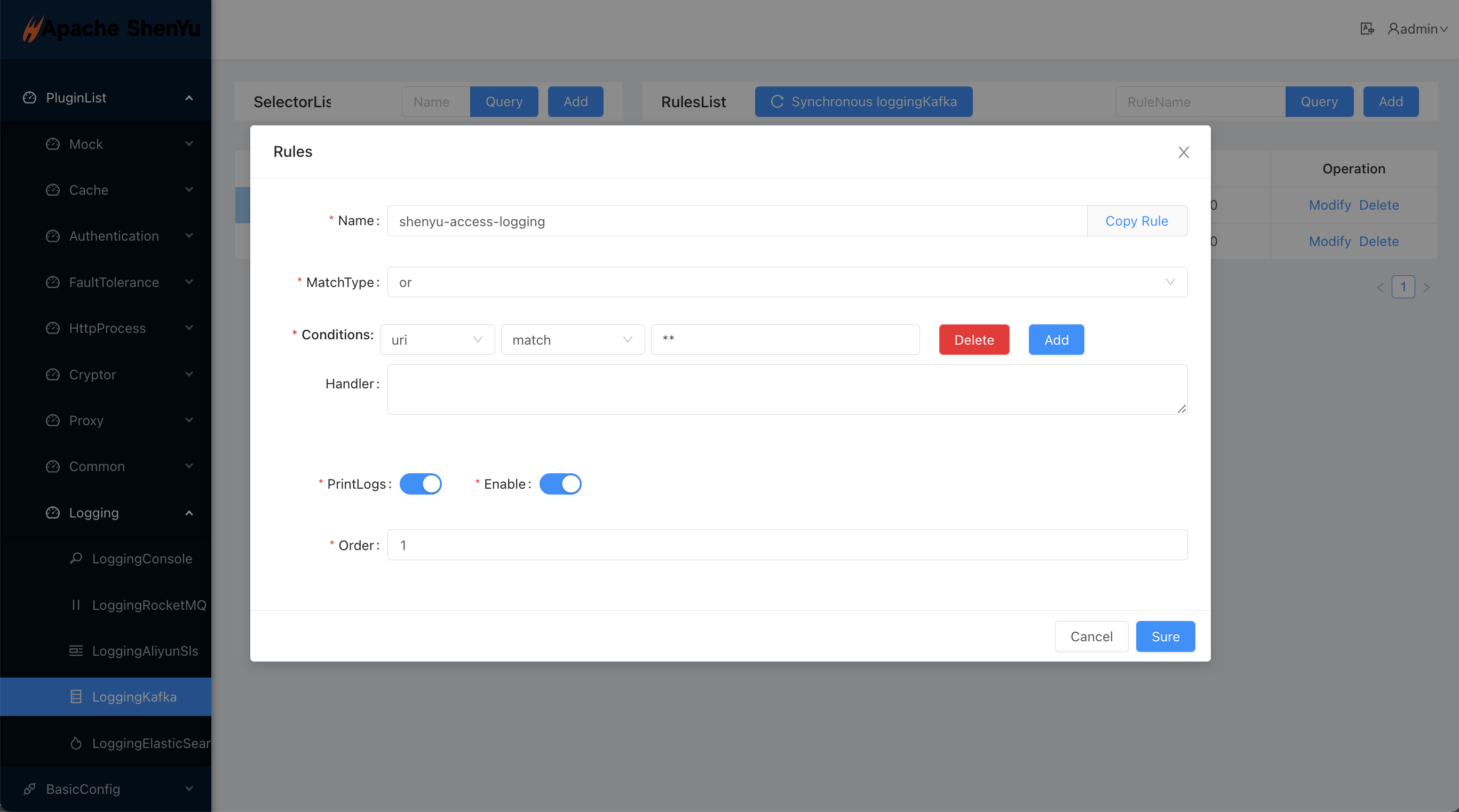
2.6.1.3 Rule Configuration
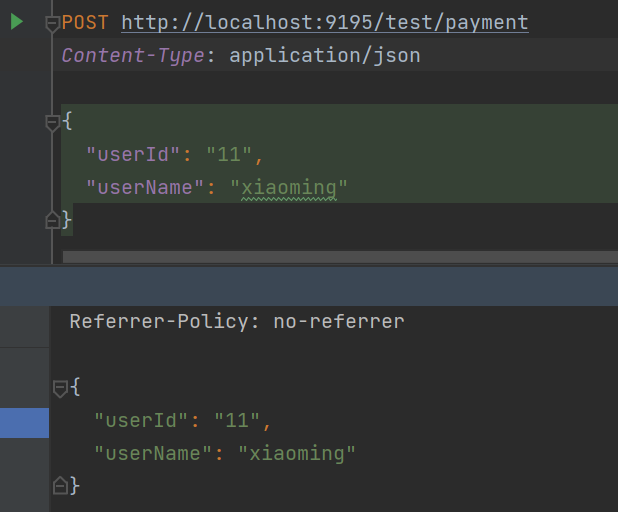
2.6.1.4 Request Service
2.6.1.5 Consumption and display of Logging
As each logging platform has differences, such as storage available clickhouse, ElasticSearch, etc., visualization has self-developed or open source Grafana, Kibana, etc..
Logging-Kafka plugin uses Kafka to decouple production and consumption, while outputting logs in json format,
consumption and visualization require users to choose different technology stacks to achieve their own situation.=
3. How to disable plugin
- In
shenyu-admin--> BasicConfig --> Plugin -->loggingKafkaset Status disable.