Apollo Data Synchronization Source Code Analysis
This article is based on the source code analysis of version 'shenyu-2.6.1'. Please refer to the official website for an introduction Data Synchronization Design.
Admin management
Understand the overall process through the process of adding plugins
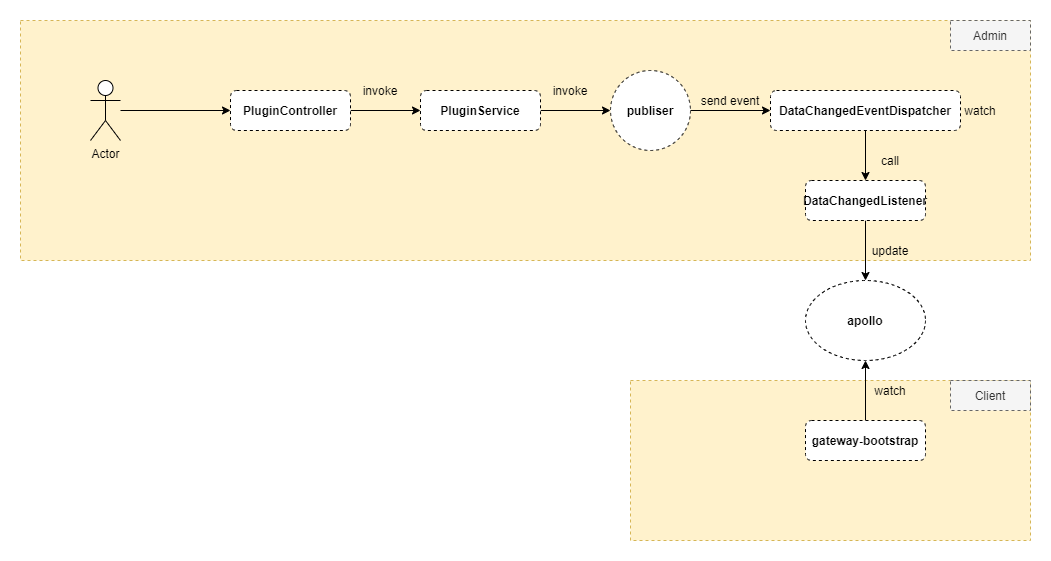
Receive Data
- PluginController.createPlugin()
Enter the createPlugin() method in the PluginController class, which is responsible for data validation, adding or updating data, and returning result information.
@Validated
@RequiredArgsConstructor
@RestController
@RequestMapping("/plugin")
public class PluginController {
@PostMapping("")
@RequiresPermissions("system:plugin:add")
public ShenyuAdminResult createPlugin(@Valid @ModelAttribute final PluginDTO pluginDTO) {
// Call pluginService.createOrUpdate for processing logic
return ShenyuAdminResult.success(pluginService.createOrUpdate(pluginDTO));
}
// ......
}
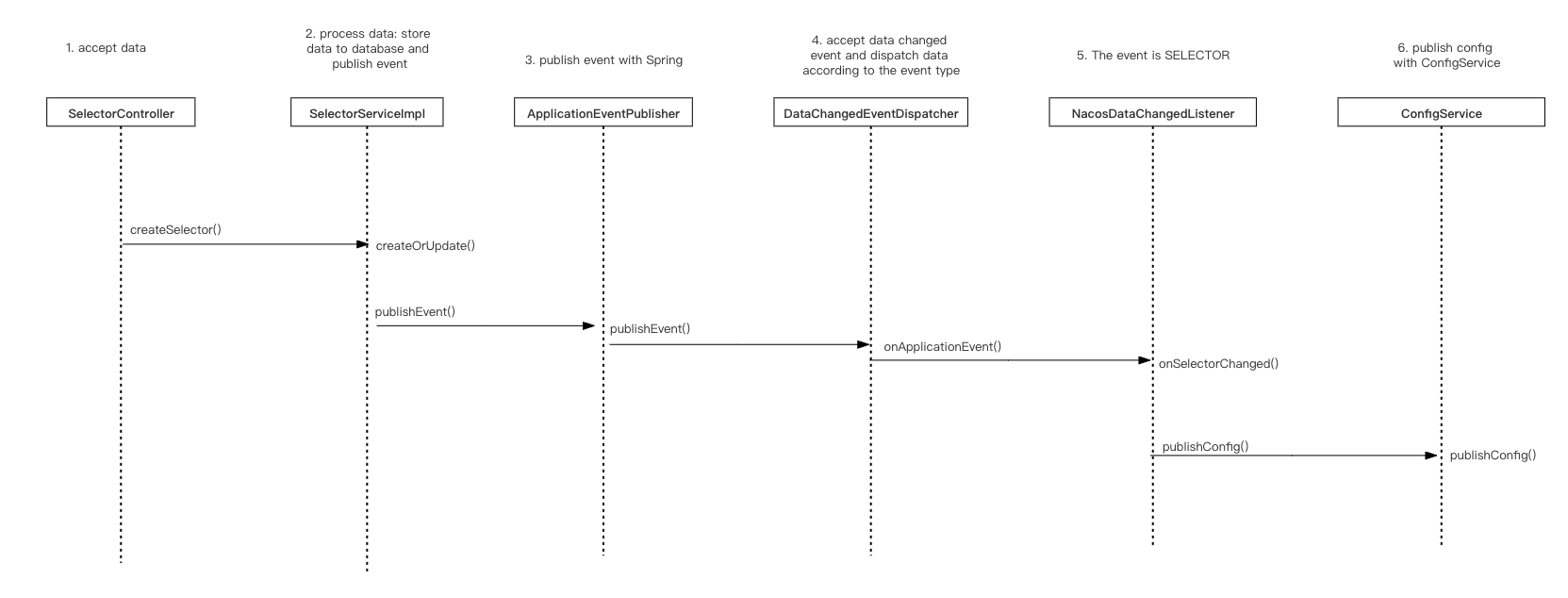
Processing data
- PluginServiceImpl.createOrUpdate() -> PluginServiceImpl.create()
Use the create() method in the PluginServiceImpl class to convert data, save it to the database, and publish events.
@RequiredArgsConstructor
@Service
public class PluginServiceImpl implements SelectorService {
// Event publishing object pluginEventPublisher
private final PluginEventPublisher pluginEventPublisher;
private String create(final PluginDTO pluginDTO) {
// Check if there is a corresponding plugin
Assert.isNull(pluginMapper.nameExisted(pluginDTO.getName()), AdminConstants.PLUGIN_NAME_IS_EXIST);
// check if Customized plugin jar
if (!Objects.isNull(pluginDTO.getFile())) {
Assert.isTrue(checkFile(Base64.decode(pluginDTO.getFile())), AdminConstants.THE_PLUGIN_JAR_FILE_IS_NOT_CORRECT_OR_EXCEEDS_16_MB);
}
// Create plugin object
PluginDO pluginDO = PluginDO.buildPluginDO(pluginDTO);
// Insert object into database
if (pluginMapper.insertSelective(pluginDO) > 0) {
// publish create event. init plugin data
pluginEventPublisher.onCreated(pluginDO);
}
return ShenyuResultMessage.CREATE_SUCCESS;
}
// ......
}
Complete the data persistence operation in the PluginServiceImpl class, that is, save the data to the database and publish events through pluginEventPublisher.
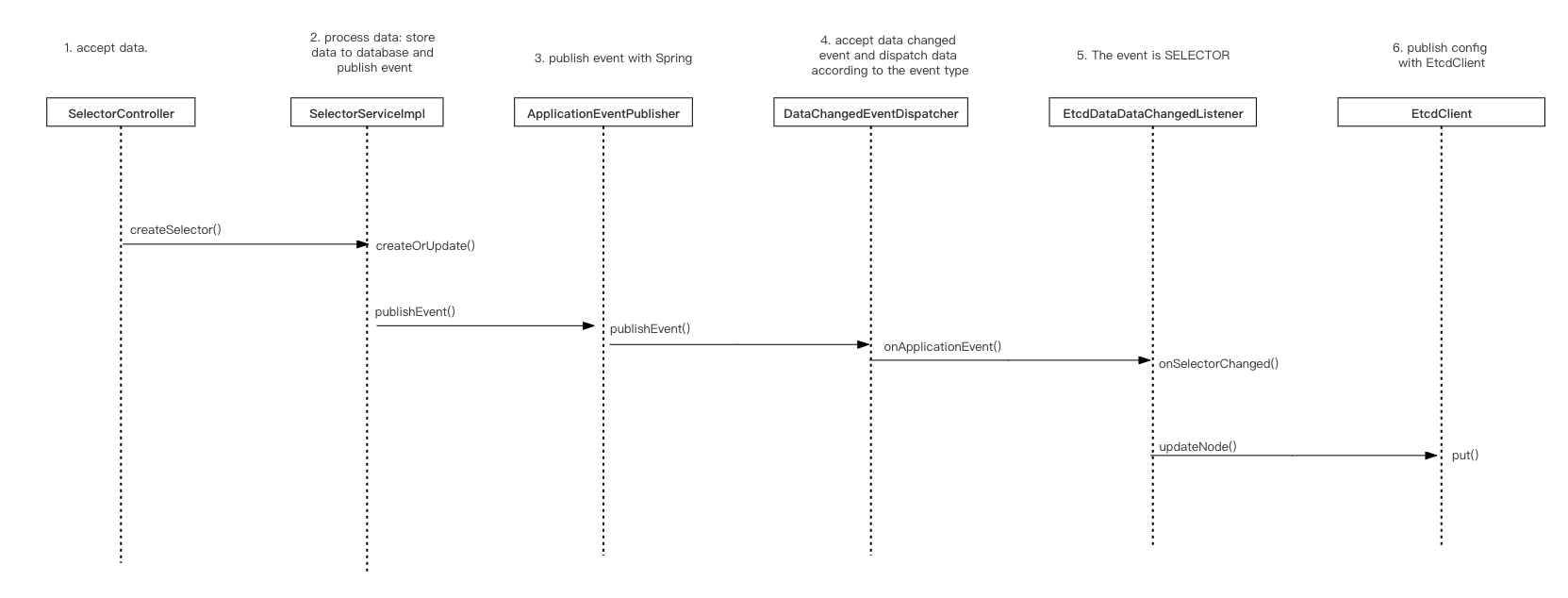
The logic of the pluginEventPublisher.onCreated method is to publish the changed event:
@Override
public void onCreated(final PluginDO plugin) {
// Publish DataChangeEvent events: event grouping (plugins, selectors, rules), event types (create, delete, update), changed data
publisher.publishEvent(new DataChangedEvent(ConfigGroupEnum.PLUGIN, DataEventTypeEnum.CREATE,
Collections.singletonList(PluginTransfer.INSTANCE.mapToData(plugin))));
// Publish PluginCreatedEvent
publish(new PluginCreatedEvent(plugin, SessionUtil.visitorName()));
}
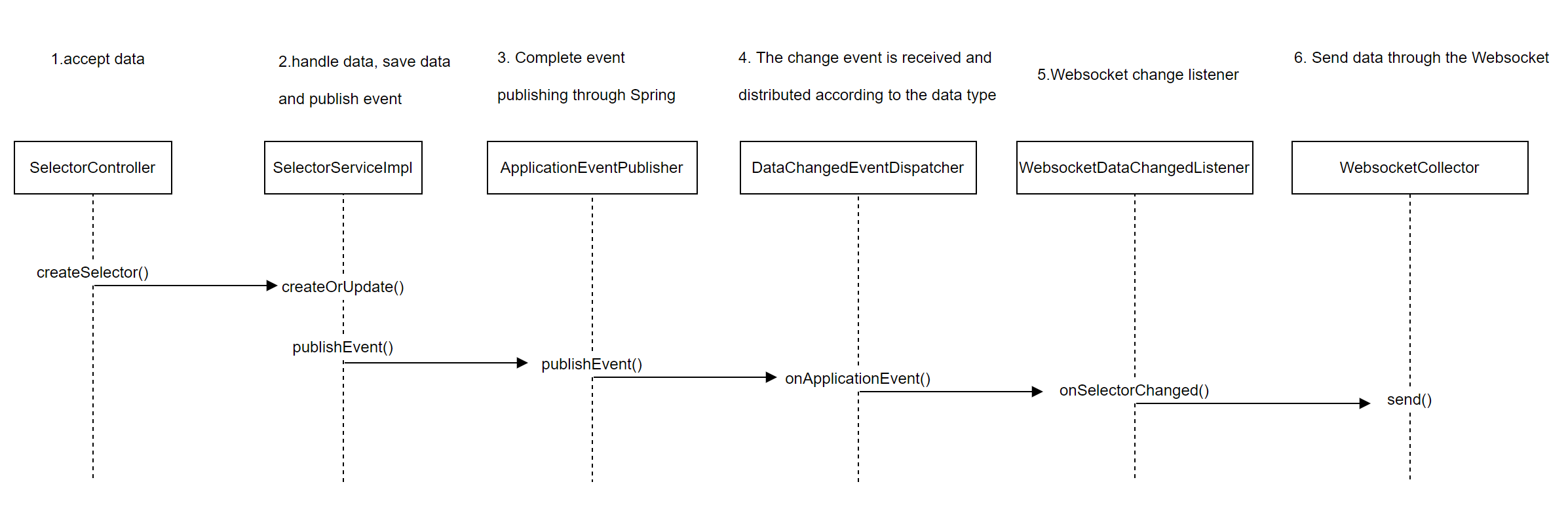
Publishing change data is completed through publisher.publishEvent(), which is an 'Application EventPublisher' object with the fully qualified name of 'org. springframework. contentxt.' Application EventPublisher `. From here, we know that publishing data is accomplished through the Spring related features.
About
ApplicationEventPublisher:When there is a state change, the publisher calls the
publishEventmethod ofApplicationEventPublisherto publish an event, theSpringcontainer broadcasts the event to all observers, and calls the observer'sonApplicationEventmethod to pass the event object to the observer. There are two ways to call thepublishEventmethod. One is to implement the interface, inject theApplicationEventPublisherobject into the container, and then call its method. The other is to call the container directly. There is not much difference between the two methods to publish events.
ApplicationEventPublisher:Publish events;ApplicationEvent:Springevents,Record the source, time, and data of the event;ApplicationListener:Event listeners, observers;
In the event publishing mechanism of Spring, there are three objects,
One is the ApplicationEventPublisher that publishes events, injecting an publisher through a constructor in ShenYu.
The other object is ApplicationEvent, which is inherited from ShenYu through DataChangedEvent, representing the event object
public class DataChangedEvent extends ApplicationEvent {
//......
}
The last one is ApplicationListener, which is implemented in ShenYu through the DataChangedEventDispatcher class as a listener for events, responsible for handling event objects.
@Component
public class DataChangedEventDispatcher implements ApplicationListener<DataChangedEvent>, InitializingBean {
//......
}
Distribute data
- DataChangedEventDispatcher.onApplicationEvent()
After the event is published, it will automatically enter the onApplicationEvent() method in the DataChangedEventDispatcher class for event processing.
@Component
public class DataChangedEventDispatcher implements ApplicationListener<DataChangedEvent>, InitializingBean {
/**
* When there is a data change, call this method
* @param event
*/
@Override
@SuppressWarnings("unchecked")
public void onApplicationEvent(final DataChangedEvent event) {
// Traverse data change listeners (only ApolloDataChangedListener will be registered here)
for (DataChangedListener listener : listeners) {
// Forward according to different grouping types
switch (event.getGroupKey()) {
case APP_AUTH: // authentication information
listener.onAppAuthChanged((List<AppAuthData>) event.getSource(), event.getEventType());
break;
case PLUGIN: // Plugin events
// Calling the registered listener object
listener.onPluginChanged((List<PluginData>) event.getSource(), event.getEventType());
break;
case RULE: // Rule events
listener.onRuleChanged((List<RuleData>) event.getSource(), event.getEventType());
break;
case SELECTOR: // Selector event
listener.onSelectorChanged((List<SelectorData>) event.getSource(), event.getEventType());
break;
case META_DATA: // Metadata events
listener.onMetaDataChanged((List<MetaData>) event.getSource(), event.getEventType());
break;
case PROXY_SELECTOR: // Proxy selector event
listener.onProxySelectorChanged((List<ProxySelectorData>) event.getSource(), event.getEventType());
break;
case DISCOVER_UPSTREAM: // Registration discovery of downstream list events
listener.onDiscoveryUpstreamChanged((List<DiscoverySyncData>) event.getSource(), event.getEventType());
applicationContext.getBean(LoadServiceDocEntry.class).loadDocOnUpstreamChanged((List<DiscoverySyncData>) event.getSource(), event.getEventType());
break;
default:
throw new IllegalStateException("Unexpected value: " + event.getGroupKey());
}
}
}
}
When there is a data change, call the onApplicationEvent method, then traverse all data change listeners, determine which data type it is, and hand it over to the corresponding data listeners for processing.
ShenYu has grouped all data into the following types: authentication information, plugin information, rule information, selector information, metadata, proxy selector, and downstream event discovery.
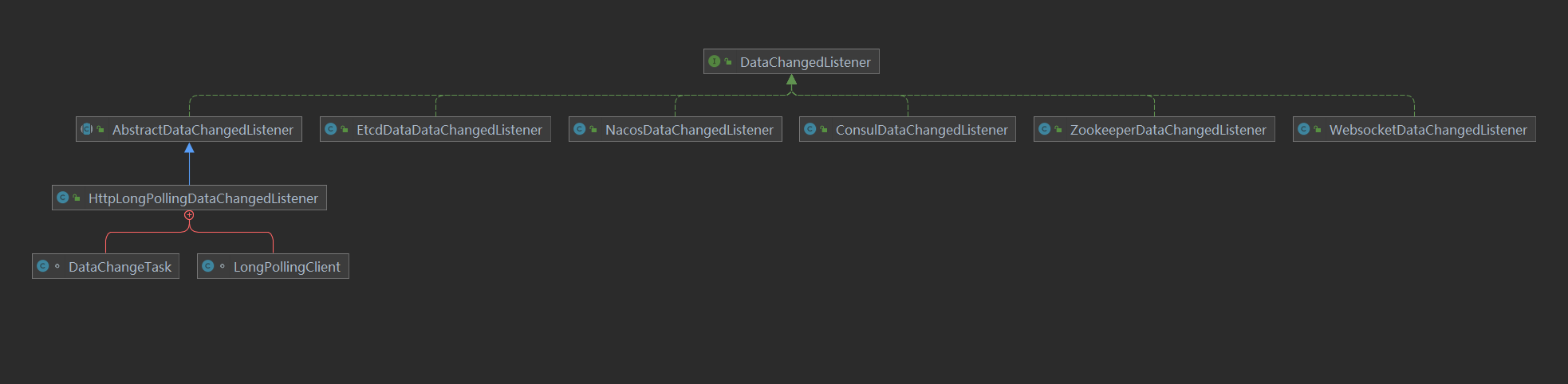
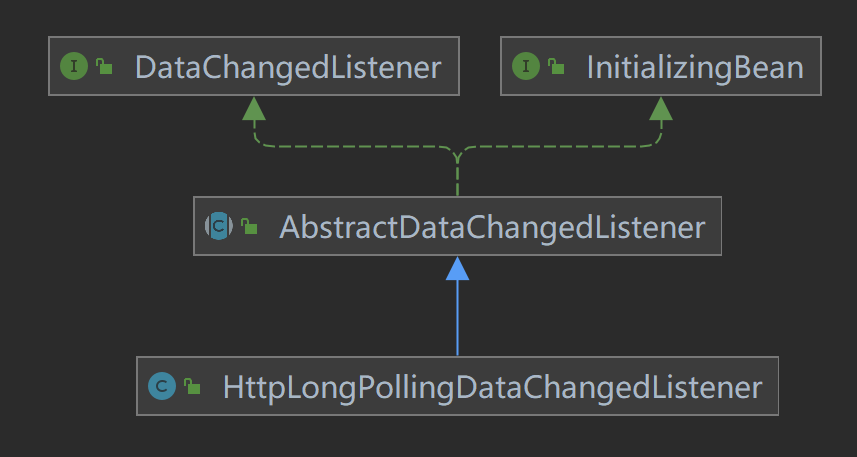
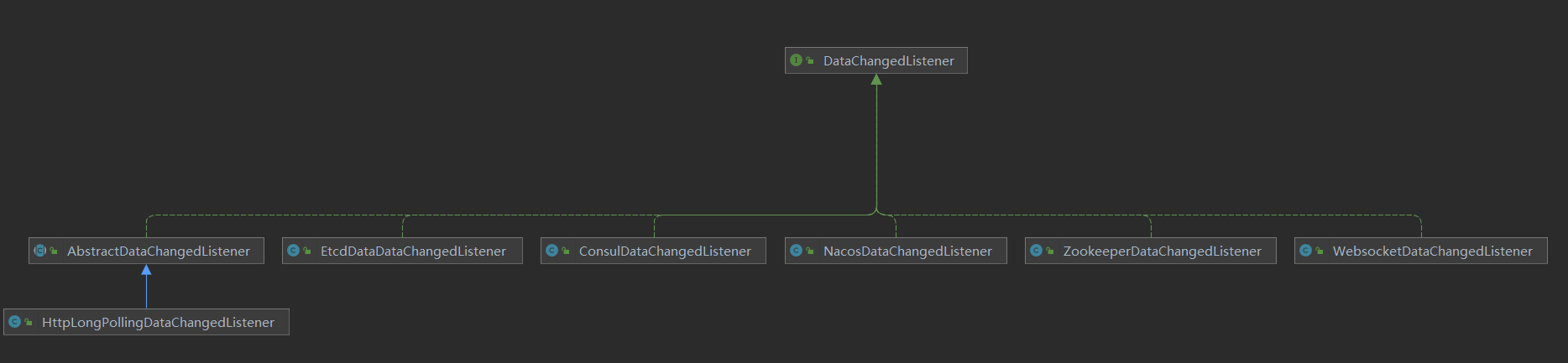
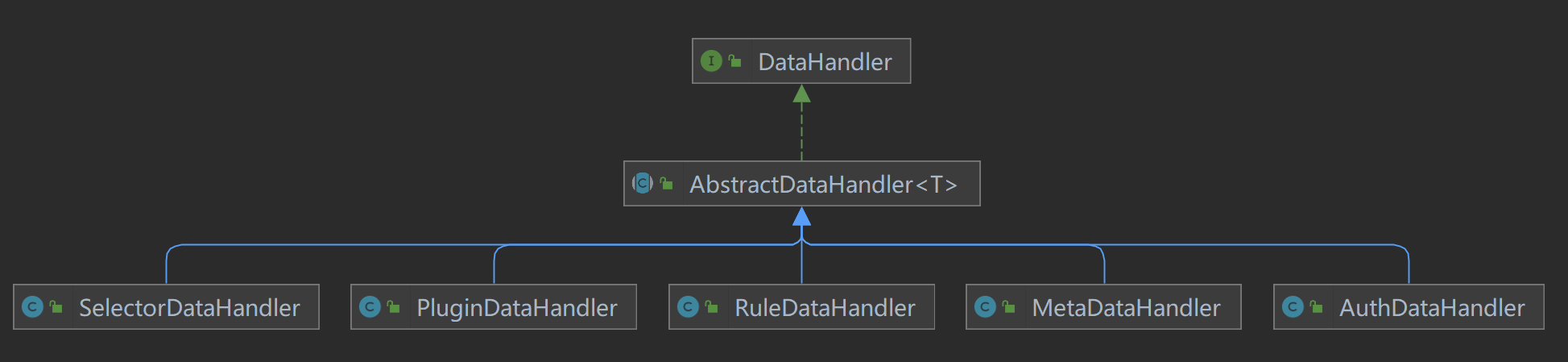
The Data Change Listener here is an abstraction of the data synchronization strategy, processed by specific implementations, and different listeners are processed by different implementations. Currently, Apollo is being analyzed
Listening, so here we only focus on ApolloDataChangedListener.
// Inheriting AbstractNodeDataChangedListener
public class ApolloDataChangedListener extends AbstractNodeDataChangedListener {
}
ApolloDataChangedListener inherits the AbstractNodeDataChangedListener class, which mainly uses key as the base class for storage, such as Apollo, Nacos, etc., while others such as Zookeeper
Consul, etc. are searched in a hierarchical manner using a path.
// Using key as the base class for finding storage methods
public abstract class AbstractNodeDataChangedListener implements DataChangedListener {
protected AbstractNodeDataChangedListener(final ChangeData changeData) {
this.changeData = changeData;
}
}
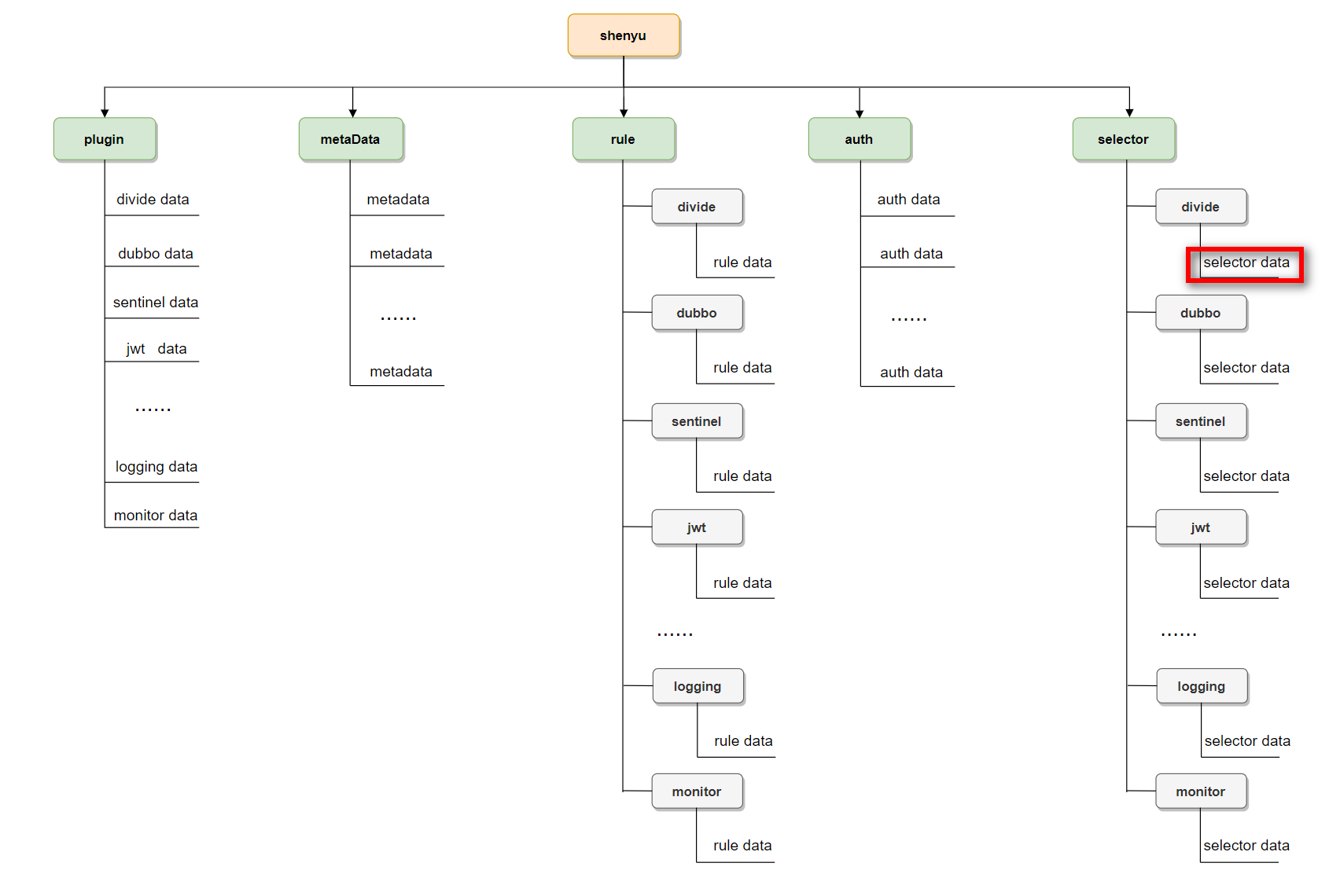
AbstractNodeDataChangedListener receives ChangeData as a parameter, which defines the key names for each data stored in Apollo. The data stored in Apollo includes the following data:
- Plugin(plugin)
- Selector(selector)
- Rules(rule)
- Authorization(auth)
- Metadata(meta)
- Proxy selector(proxy.selector)
- Downstream List (discovery)
These information are specified by the ApolloDataChangedListener constructor:
public class ApolloDataChangedListener extends AbstractNodeDataChangedListener {
public ApolloDataChangedListener(final ApolloClient apolloClient) {
// Configure prefixes for several types of grouped data
super(new ChangeData(ApolloPathConstants.PLUGIN_DATA_ID,
ApolloPathConstants.SELECTOR_DATA_ID,
ApolloPathConstants.RULE_DATA_ID,
ApolloPathConstants.AUTH_DATA_ID,
ApolloPathConstants.META_DATA_ID,
ApolloPathConstants.PROXY_SELECTOR_DATA_ID,
ApolloPathConstants.DISCOVERY_DATA_ID));
// Manipulating objects of Apollo
this.apolloClient = apolloClient;
}
}
DataChangedListener defines the following methods:
// Data Change Listener
public interface DataChangedListener {
// Call when authorization information changes
default void onAppAuthChanged(List<AppAuthData> changed, DataEventTypeEnum eventType) {
}
// Called when plugin information changes
default void onPluginChanged(List<PluginData> changed, DataEventTypeEnum eventType) {
}
// Called when selector information changes
default void onSelectorChanged(List<SelectorData> changed, DataEventTypeEnum eventType) {
}
// Called when metadata information changes
default void onMetaDataChanged(List<MetaData> changed, DataEventTypeEnum eventType) {
}
// Call when rule information changes
default void onRuleChanged(List<RuleData> changed, DataEventTypeEnum eventType) {
}
// Called when proxy selector changes
default void onProxySelectorChanged(List<ProxySelectorData> changed, DataEventTypeEnum eventType) {
}
// Called when downstream information changes are discovered
default void onDiscoveryUpstreamChanged(List<DiscoverySyncData> changed, DataEventTypeEnum eventType) {
}
}
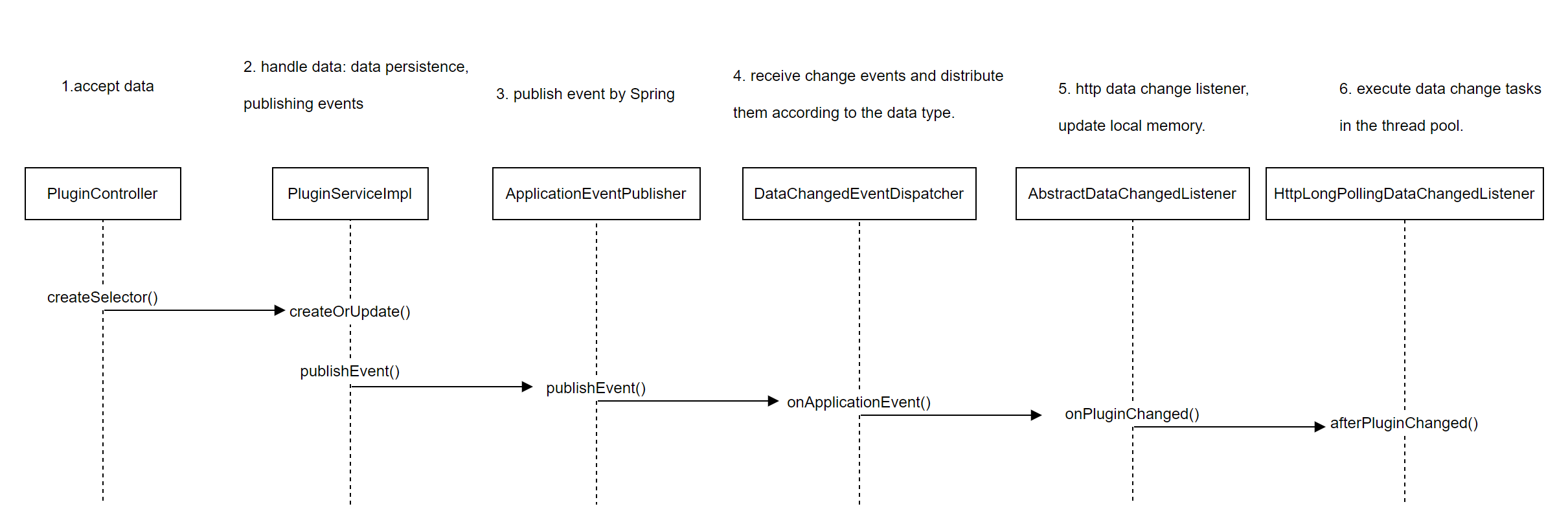
When the plugin is processed by DataChangedEventDispatcher, the method listener.onPluginChanged is called. Next, analyze the logic of the object and implement the processing by AbstractNodeDataChangedListener:
public abstract class AbstractNodeDataChangedListener implements DataChangedListener {
@Override
public void onPluginChanged(final List<PluginData> changed, final DataEventTypeEnum eventType) {
//Configure prefix as plugin.
final String configKeyPrefix = changeData.getPluginDataId() + DefaultNodeConstants.JOIN_POINT;
this.onCommonChanged(configKeyPrefix, changed, eventType, PluginData::getName, PluginData.class);
LOG.debug("[DataChangedListener] PluginChanged {}", configKeyPrefix);
}
}
Firstly, the key prefix for constructing configuration data is: plugin., Call onCommonChanged again for unified processing:
private <T> void onCommonChanged(final String configKeyPrefix, final List<T> changedList,
final DataEventTypeEnum eventType, final Function<? super T, ? extends String> mapperToKey,
final Class<T> tClass) {
// Avoiding concurrent operations on list nodes
final ReentrantLock reentrantLock = listSaveLockMap.computeIfAbsent(configKeyPrefix, key -> new ReentrantLock());
try {
reentrantLock.lock();
// Current incoming plugin list
final List<String> changeNames = changedList.stream().map(mapperToKey).collect(Collectors.toList());
switch (eventType) {
// Delete Operation
case DELETE:
// delete plugin.${pluginName}
changedList.stream().map(mapperToKey).forEach(removeKey -> {
delConfig(configKeyPrefix + removeKey);
});
// Remove the corresponding plugin name from plugin. list
// The plugin.list records the currently enabled list
delChangedData(configKeyPrefix, changeNames);
break;
case REFRESH:
case MYSELF:
// Overload logic
// Get a list of all plugins in plugin.list
final List<String> configDataNames = this.getConfigDataNames(configKeyPrefix);
// Update each currently adjusted plug-in in turn
changedList.forEach(changedData -> {
// Publish Configuration
publishConfig(configKeyPrefix + mapperToKey.apply(changedData), changedData);
});
// If there is more data in the currently stored list than what is currently being passed in, delete the excess data
if (configDataNames != null && configDataNames.size() > changedList.size()) {
// Kick out the currently loaded data
configDataNames.removeAll(changeNames);
// Delete cancelled data one by one
configDataNames.forEach(this::delConfig);
}
// Update list data again
publishConfig(configKeyPrefix + DefaultNodeConstants.LIST_STR, changeNames);
break;
default:
// Add or update
changedList.forEach(changedData -> {
publishConfig(configKeyPrefix + mapperToKey.apply(changedData), changedData);
});
// Update the newly added plugin
putChangeData(configKeyPrefix, changeNames);
break;
}
} catch (Exception e) {
LOG.error("AbstractNodeDataChangedListener onCommonMultiChanged error ", e);
} finally {
reentrantLock.unlock();
}
}
In the above logic, it actually includes the handling of full overloading (REFRESH, MYSELF) and increment (Delete, UPDATE, CREATE)
The plugin mainly includes two nodes:
plugin.listList of currently effective pluginsplugin.${plugin.name}Detailed information on specific plugins Finally, write the data corresponding to these two nodes into Apollo.
Data initialization
After starting admin, the current data information will be fully synchronized to Apollo, which is implemented by ApolloDataChangedInit:
// Inheriting AbstractDataChangedInit
public class ApolloDataChangedInit extends AbstractDataChangedInit {
// Apollo operation object
private final ApolloClient apolloClient;
public ApolloDataChangedInit(final ApolloClient apolloClient) {
this.apolloClient = apolloClient;
}
@Override
protected boolean notExist() {
// Check if nodes such as plugin, auth, meta, proxy.selector exist
// As long as one does not exist, it enters reload (these nodes will not be created, why check once?)
return Stream.of(ApolloPathConstants.PLUGIN_DATA_ID, ApolloPathConstants.AUTH_DATA_ID, ApolloPathConstants.META_DATA_ID, ApolloPathConstants.PROXY_SELECTOR_DATA_ID).allMatch(
this::dataIdNotExist);
}
/**
* Data id not exist boolean.
*
* @param pluginDataId the plugin data id
* @return the boolean
*/
private boolean dataIdNotExist(final String pluginDataId) {
return Objects.isNull(apolloClient.getItemValue(pluginDataId));
}
}
Check if there is data in apollo, and if it does not exist, synchronize it.
There is a bug here because the key determined here will not be created during synchronization, which will cause data to be reloaded every time it is restarted. PR#5435
ApolloDataChangedInit implements the CommandLineRunner interface. It is an interface provided by springboot that executes the run() method after all Spring Beans are initialized. It is commonly used for initialization operations in projects.
- SyncDataService.syncAll()
Query data from the database, then perform full data synchronization, including all authentication information, plugin information, rule information, selector information, metadata, proxy selector, and discover downstream events. Mainly, synchronization events are published through eventPublisher. After publishing events through publishEvent(), ApplicationListener performs event change operations, which is referred to as DataChangedEventDispatcher in ShenYu.
@Service
public class SyncDataServiceImpl implements SyncDataService {
// Event Publishing
private final ApplicationEventPublisher eventPublisher;
/***
* Full data synchronization
* @param type the type
* @return
*/
@Override
public boolean syncAll(final DataEventTypeEnum type) {
// Synchronize auth data
appAuthService.syncData();
// Synchronize plugin data
List<PluginData> pluginDataList = pluginService.listAll();
//Notify subscribers through the Spring publish/subscribe mechanism (publishing DataChangedEvent)
//Unified monitoring by DataChangedEventDispatcher
//DataChangedEvent comes with configuration grouping type, current operation type, and data
eventPublisher.publishEvent(new DataChangedEvent(ConfigGroupEnum.PLUGIN, type, pluginDataList));
// synchronizing selector
List<SelectorData> selectorDataList = selectorService.listAll();
eventPublisher.publishEvent(new DataChangedEvent(ConfigGroupEnum.SELECTOR, type, selectorDataList));
// Synchronization rules
List<RuleData> ruleDataList = ruleService.listAll();
eventPublisher.publishEvent(new DataChangedEvent(ConfigGroupEnum.RULE, type, ruleDataList));
// Synchronization metadata
metaDataService.syncData();
// Synchronization Downstream List
discoveryService.syncData();
return true;
}
}
Bootstrap synchronization operation initialization
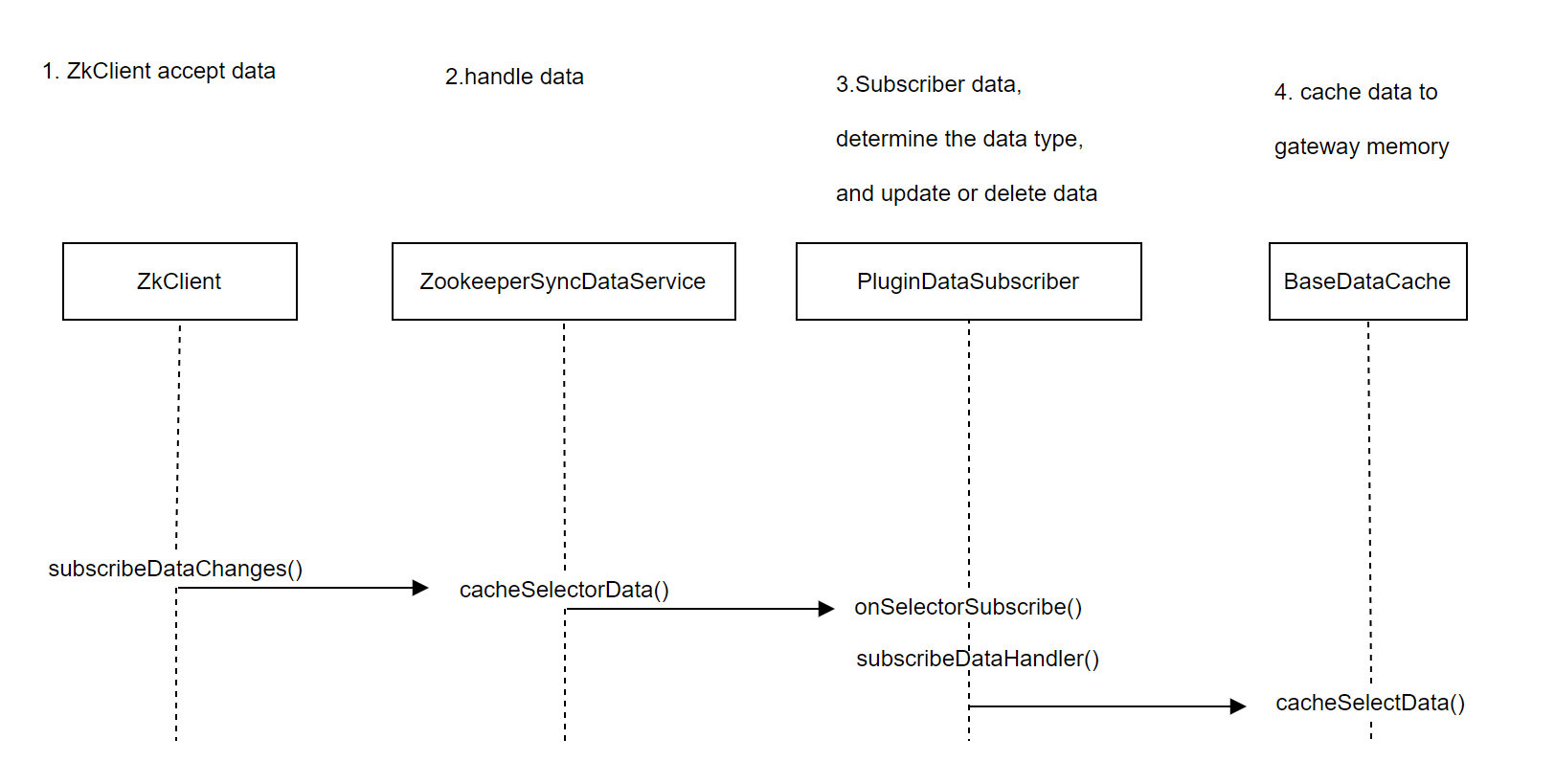
The data synchronization initialization operation on the gateway side mainly involves subscribing to nodes in apollo, and receiving changed data when there are changes. This depends on the listener mechanism of apollo. In ShenYu, the person responsible for Apollo data synchronization is ApolloDataService.
The functional logic of Apollo DataService is completed during the instantiation process: subscribe to the shenyu data synchronization node in Apollo. Implement through the configService.addChangeListener() method;
public class ApolloDataService extends AbstractNodeDataSyncService implements SyncDataService {
public ApolloDataService(final Config configService, final PluginDataSubscriber pluginDataSubscriber,
final List<MetaDataSubscriber> metaDataSubscribers,
final List<AuthDataSubscriber> authDataSubscribers,
final List<ProxySelectorDataSubscriber> proxySelectorDataSubscribers,
final List<DiscoveryUpstreamDataSubscriber> discoveryUpstreamDataSubscribers) {
// Configure the prefix for listening
super(new ChangeData(ApolloPathConstants.PLUGIN_DATA_ID,
ApolloPathConstants.SELECTOR_DATA_ID,
ApolloPathConstants.RULE_DATA_ID,
ApolloPathConstants.AUTH_DATA_ID,
ApolloPathConstants.META_DATA_ID,
ApolloPathConstants.PROXY_SELECTOR_DATA_ID,
ApolloPathConstants.DISCOVERY_DATA_ID),
pluginDataSubscriber, metaDataSubscribers, authDataSubscribers, proxySelectorDataSubscribers, discoveryUpstreamDataSubscribers);
this.configService = configService;
// Start listening
// Note: The Apollo method is only responsible for obtaining data from Apollo and adding it to the local cache, and does not handle listening
startWatch();
// Configure listening
apolloWatchPrefixes();
}
}
Firstly, configure the key information that needs to be processed and synchronize it with the admin's key. Next, call the startWatch() method to process data acquisition and listening. But in the implementation of Apollo, this method is only responsible for handling data retrieval and setting it to the local cache.
Listening is handled by the apolloWatchPrefixes method
private void apolloWatchPrefixes() {
// Defining Listeners
final ConfigChangeListener listener = changeEvent -> {
changeEvent.changedKeys().forEach(changeKey -> {
try {
final ConfigChange configChange = changeEvent.getChange(changeKey);
// Skip if not changed
if (configChange == null) {
LOG.error("apollo watchPrefixes error configChange is null {}", changeKey);
return;
}
final String newValue = configChange.getNewValue();
// skip last is "list"
// If it is a Key at the end of the list, such as plugin.list, skip it because it is only a list that records the effectiveness and will not be cached locally
final int lastListStrIndex = changeKey.length() - DefaultNodeConstants.LIST_STR.length();
if (changeKey.lastIndexOf(DefaultNodeConstants.LIST_STR) == lastListStrIndex) {
return;
}
// If it starts with plugin. => Process plugin data
if (changeKey.indexOf(ApolloPathConstants.PLUGIN_DATA_ID) == 0) {
// delete
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
// clear cache
unCachePluginData(changeKey);
} else {
// update cache
cachePluginData(newValue);
}
// If it starts with selector. => Process selector data
} else if (changeKey.indexOf(ApolloPathConstants.SELECTOR_DATA_ID) == 0) {
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
unCacheSelectorData(changeKey);
} else {
cacheSelectorData(newValue);
}
// If it starts with rule. => Process rule data
} else if (changeKey.indexOf(ApolloPathConstants.RULE_DATA_ID) == 0) {
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
unCacheRuleData(changeKey);
} else {
cacheRuleData(newValue);
}
// If it starts with auth. => Process auth data
} else if (changeKey.indexOf(ApolloPathConstants.AUTH_DATA_ID) == 0) {
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
unCacheAuthData(changeKey);
} else {
cacheAuthData(newValue);
}
// If it starts with meta. => Process meta data
} else if (changeKey.indexOf(ApolloPathConstants.META_DATA_ID) == 0) {
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
unCacheMetaData(changeKey);
} else {
cacheMetaData(newValue);
}
// If it starts with proxy.selector. => Process proxy.selector meta
} else if (changeKey.indexOf(ApolloPathConstants.PROXY_SELECTOR_DATA_ID) == 0) {
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
unCacheProxySelectorData(changeKey);
} else {
cacheProxySelectorData(newValue);
}
// If it starts with discovery. => Process discovery meta
} else if (changeKey.indexOf(ApolloPathConstants.DISCOVERY_DATA_ID) == 0) {
if (PropertyChangeType.DELETED.equals(configChange.getChangeType())) {
unCacheDiscoveryUpstreamData(changeKey);
} else {
cacheDiscoveryUpstreamData(newValue);
}
}
} catch (Exception e) {
LOG.error("apollo sync listener change key handler error", e);
}
});
};
watchConfigChangeListener = listener;
// Add listening
configService.addChangeListener(listener, Collections.emptySet(), ApolloPathConstants.pathKeySet());
}
The logic of loading data from the previous admin will only add two keys to the plugin: plugin.list and plugin.${plugin.name}, while plugin.list is a list of all enabled plugins, and the data for this key is in the
There is no data in the local cache, only `plugin${plugin.name} will be focus.
At this point, the synchronization logic of bootstrap in apollo has been analyzed.