LoadBalancer SPI Source Code Analysis
Gateway applications need to support a variety of load balancing strategies, including random,Hashing, RoundRobin and so on. In Apache Shenyu gateway, it not only realizes such traditional algorithms, but also makes smoother traffic processing for the entry of server nodes through detailed processing such as traffic warm-up, so as to obtain better overall stability. In this article, let's walk through how Apache Shenyu is designed and implemented this part of the function.
This article based on
shenyu-2.5.0version of the source code analysis.
[TOC]
LoadBalancer SPI
The implementation of LoadBalancer is in shenyu-loadbalancer module. It has based on its SPI creation mechanism. The core interface code is shown as follows. This interface well explains the concept: load balancing is to select the most appropriate node from a series of server nodes. Routing, traffic processing and load balancing is the basic function of LoadBalancer SPI.
@SPI
public interface LoadBalancer {
/**
* this is select one for upstream list.
*
* @param upstreamList upstream list
* @param ip ip
* @return upstream
*/
Upstream select(List<Upstream> upstreamList, String ip);
}
Where upstreamList represents the server nodes list available for routing. Upstream is the data structure of server node, the important elements including protocol, upstreamUrl , weight, timestamp, warmup、healthy.
public class Upstream {
/**
* protocol.
*/
private final String protocol;
/**
* url.
*/
private String url;
/**
* weight.
*/
private final int weight;
/**
* false close, true open.
*/
private boolean status;
/**
* startup time.
*/
private final long timestamp;
/**
* warmup.
*/
private final int warmup;
/**
* healthy.
*/
private boolean healthy;
/**
* lastHealthTimestamp.
*/
private long lastHealthTimestamp;
/**
* lastUnhealthyTimestamp.
*/
private long lastUnhealthyTimestamp;
/**
* group.
*/
private String group;
/**
* version.
*/
private String version;
}
Design of LoadBalancer module
The class diagram of LoadBalancer moduleisshown as follows.
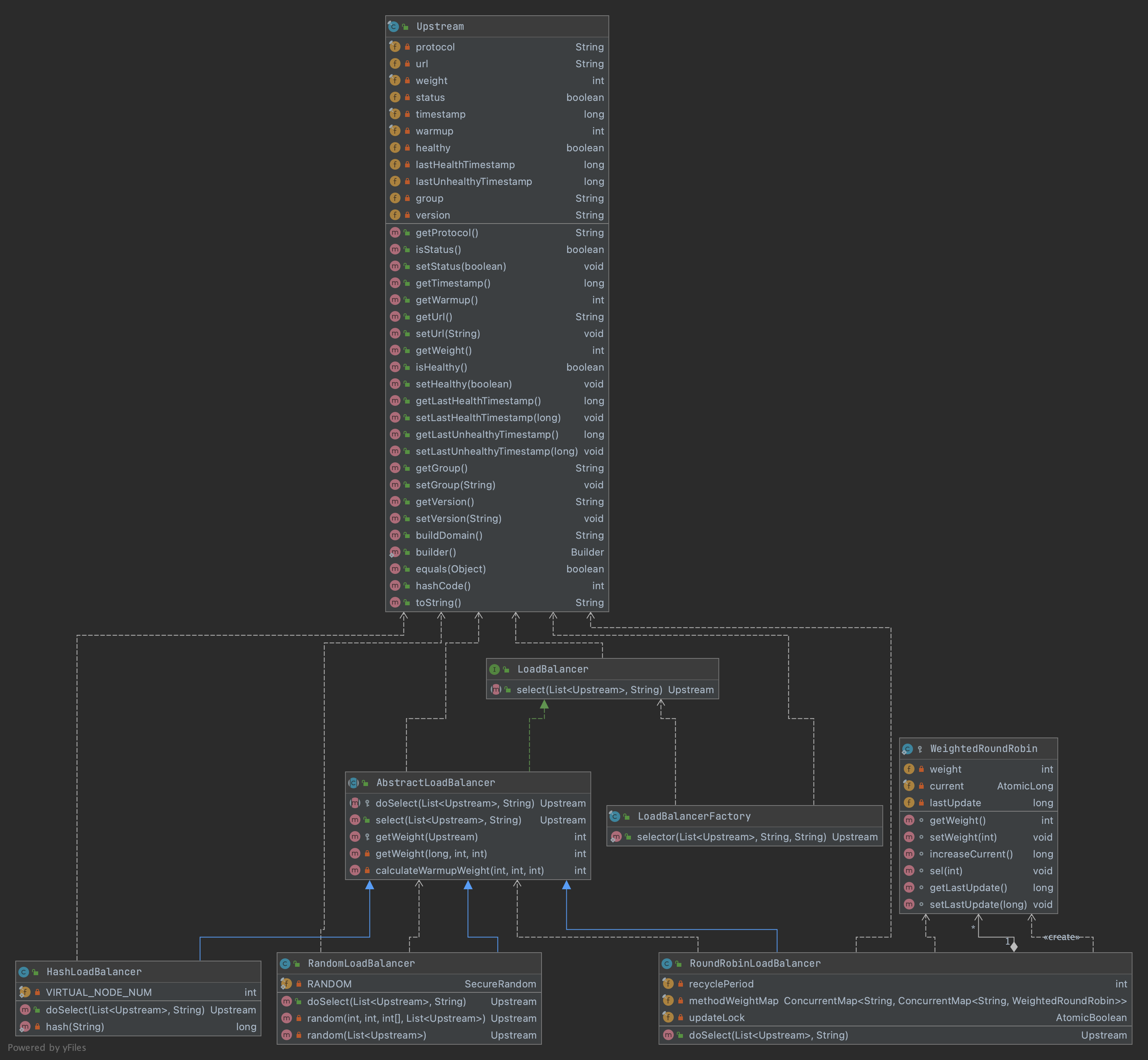
We can draw the outline of LoadBalancer module from the class diagram:
-
The abstract class
AbstractLoadBalancerimplements the SPILoadBalancerinterface,and supplies the template methods for selection related, such as select(), selector(),and gives the calculation of weight. -
Three implementation classes which inherit
AbstractLoadBalancerto realize their own logic:RandomLoadBalancer- Weight RandomHashLoadBalancer- Consistent HashingRoundRobinLoadBalancer-Weight Round Robin per-packet
-
The factory class
LoadBalancerFactoryprovides public static method to be called.The implementation classes and algorithms are configurable. According to its specification, by adding profile in
SHENYU_DIERECTORYdirectory, the data in profile should be key=value-class format, where the value-class will be load by theApache Shenyu SPIclass loader, and key value should be annamedefined inLoadBalanceEnum.
random=org.apache.shenyu.loadbalancer.spi.RandomLoadBalancer
roundRobin=org.apache.shenyu.loadbalancer.spi.RoundRobinLoadBalancer
hash=org.apache.shenyu.loadbalancer.spi.HashLoadBalancer
The code of LoadBalanceEnum is as follows:
public enum LoadBalanceEnum {
/**
* Hash load balance enum.
*/
HASH(1, "hash", true),
/**
* Random load balance enum.
*/
RANDOM(2, "random", true),
/**
* Round robin load balance enum.
*/
ROUND_ROBIN(3, "roundRobin", true);
private final int code;
private final String name;
private final boolean support;
}
AbstractLoadBalancer
This abstract class implements the LoadBalancer interface and define the abstract method doSelect() to be processed by the implementation classes. In the template method select(), It will do validation first then call the doSelect() method.
public abstract class AbstractLoadBalancer implements LoadBalancer {
/**
* Do select divide upstream.
*
* @param upstreamList the upstream list
* @param ip the ip
* @return the divide upstream
*/
protected abstract Upstream doSelect(List<Upstream> upstreamList, String ip);
@Override
public Upstream select(final List<Upstream> upstreamList, final String ip) {
if (CollectionUtils.isEmpty(upstreamList)) {
return null;
}
if (upstreamList.size() == 1) {
return upstreamList.get(0);
}
return doSelect(upstreamList, ip);
}
}
When the timestamp of server node is not null, and the interval between current time and timestamp is within the traffic warm-up time, the formula for weight calculation is.
$$ 0
ww = min(1,uptime/(warmup/weight))
$$
It can be seen from the formula that the final weight(ww) is proportional to the original-weight value. The closer the time interval is to the warmup time, the greater the final ww. That is, the longer the waiting time of the request, the higher the final weight. When there is no timestamp or other conditions, the ww is equal to the weight value of Upstream object.
The central of thinking about warm-upis to avoid bad performance when adding new server and the new JVMs starting up.
Let's see how the load balancing with Random, Hashing and RoundRobin strategy is implemented.
RandomLoadBalancer
The RandomLoadBalancer can handle two situations:
- Each node without weight, or every node has the same weight, randomly choose one.
- Server Nodes with different weight, choose one randomly by weight.
Following is the random() method of RandomLoadBalancer. When traversing server node list, if the randomly generated value is less than the weight of node, then the current node will be chosen. If after one round traversing, there is no server node match, then it will choose one randomly. The getWeight(final Upstream upstream) is defined in AbstractLoadBalancer class.
@Override
public Upstream doSelect(final List<Upstream> upstreamList, final String ip) {
int length = upstreamList.size();
// every upstream has the same weight?
boolean sameWeight = true;
// the weight of every upstream
int[] weights = new int[length];
int firstUpstreamWeight = getWeight(upstreamList.get(0));
weights[0] = firstUpstreamWeight;
// init the totalWeight
int totalWeight = firstUpstreamWeight;
int halfLengthTotalWeight = 0;
for (int i = 1; i < length; i++) {
int currentUpstreamWeight = getWeight(upstreamList.get(i));
if (i <= (length + 1) / 2) {
halfLengthTotalWeight = totalWeight;
}
weights[i] = currentUpstreamWeight;
totalWeight += currentUpstreamWeight;
if (sameWeight && currentUpstreamWeight != firstUpstreamWeight) {
// Calculate whether the weight of ownership is the same.
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
return random(totalWeight, halfLengthTotalWeight, weights, upstreamList);
}
return random(upstreamList);
}
private Upstream random(final int totalWeight, final int halfLengthTotalWeight, final int[] weights, final List<Upstream> upstreamList) {
// If the weights are not the same and the weights are greater than 0, then random by the total number of weights.
int offset = RANDOM.nextInt(totalWeight);
int index = 0;
int end = weights.length;
if (offset >= halfLengthTotalWeight) {
index = (weights.length + 1) / 2;
offset -= halfLengthTotalWeight;
} else {
end = (weights.length + 1) / 2;
}
// Determine which segment the random value falls on
for (; index < end; index++) {
offset -= weights[index];
if (offset < 0) {
return upstreamList.get(index);
}
}
return random(upstreamList);
}
HashLoadBalancer
In HashLoadBalancer, it takes the advantages of consistent hashing , that maps both the input traffic and the servers to a unit circle, or name as hash ring. For the requestedip address, with its hash value to find the node closest in clockwise order as the node to be routed. Let's see how consistent hashing is implemented in HashLoadBalancer.
As to the hash algorithms, HashLoadBalancer uses MD5 hash, which has the advantage of mixing the input in an unpredictable but deterministic way. The output is a 32-bit integer. the code is shown as follows:
private static long hash(final String key) {
// md5 byte
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new ShenyuException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes;
keyBytes = key.getBytes(StandardCharsets.UTF_8);
md5.update(keyBytes);
byte[] digest = md5.digest();
// hash code, Truncate to 32-bits
long hashCode = (long) (digest[3] & 0xFF) << 24
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
return hashCode & 0xffffffffL;
}
Importantly, how to generate the hash ring and avoid skewness? Let's thedoSelect() method inHashLoadBalancer as follows:
private static final int VIRTUAL_NODE_NUM = 5;
@Override
public Upstream doSelect(final List<Upstream> upstreamList, final String ip) {
final ConcurrentSkipListMap<Long, Upstream> treeMap = new ConcurrentSkipListMap<>();
upstreamList.forEach(upstream -> IntStream.range(0, VIRTUAL_NODE_NUM).forEach(i -> {
long addressHash = hash("SHENYU-" + upstream.getUrl() + "-HASH-" + i);
treeMap.put(addressHash, upstream);
}));
long hash = hash(ip);
SortedMap<Long, Upstream> lastRing = treeMap.tailMap(hash);
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
return treeMap.firstEntry().getValue();
}
In this method, duplicated labels are used which are called "virtual nodes" (i.e. 5 virtual nodes point to a single "real" server). It will make the distribution in hash ring more evenly, and reduce the occurrence of data skewness.
In order to rescue the data sorted in the hash ring, and can be accessed quickly, we use ConcurrentSkipListMap of Java to store the server node lists ( with virtual nodes) and its hash value as key. This class a member of Java Collections Framework, providing expected average log(n) time cost for retrieve and access operations safely execute concurrent by multiple threads.
Furthermore, the method tailMap(K fromKey) of ConcurrentSkipListMap can return a view of portion of the map whose keys are greater or equal to the fromKey, and not need to navigate the whole map.
In the above code section, after the hash ring is generated, it uses tailMap(K fromKey) of ConcurrentSkipListMap to find the subset that the elements greater, or equal to the hash value of the requested ip, its first element is just the node to be routed. With the suitable data structure, the code looks particularly clear and concise.
Consistent hashing resolved the poor scalability of the traditional hashing by modular operation.
RoundRobinLoadBalancer
The original Round-robin selection is to select server nodes one by one from the candidate list. Whenever some nodes has crash ( ex, cannot be connected after 1 minute), it will be removed from the candidate list, and do not attend the next round, until the server node is recovered and it will be add to the candidate list again. In RoundRobinLoadBalancer,the weight Round Robin per-packet schema is implemented.
In order to work in concurrent system, it provides an inner static class WeigthRoundRobin to store and calculate the rolling selections of each server node. Following is the main section of this class( removed remark )
protected static class WeightedRoundRobin {
private int weight;
private final AtomicLong current = new AtomicLong(0);
private long lastUpdate;
void setWeight(final int weight) {
this.weight = weight;
current.set(0);
}
long increaseCurrent() {
return current.addAndGet(weight);
}
void sel(final int total) {
current.addAndGet(-1 * total);
}
void setLastUpdate(final long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
Please focus on the these method:
-
setWeight(final int weight): set the current value by weight -
increaseCurrent(): Increment thecurrentvalue byweight, andcurrentset to 0. -
sel(final int total): decrement thecurrentvalue by totalLet's see how the weight factor being used in this round-robin selection?
First it defines a two-level
ConcurrentMaptype variable named asmethodWeightMap, to cache the server node lists and the rolling selection data about each server node.
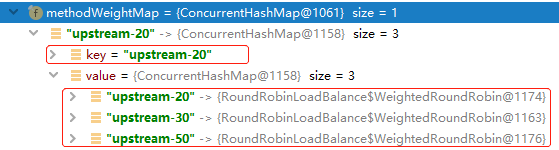
private final ConcurrentMap<String, ConcurrentMap<String, WeightedRoundRobin>> methodWeightMap = new ConcurrentHashMap<>(16);
In this map, the key of first level is set to upstreamUrl of first element in server node list. The type of second object is ConcurrentMap<String, WeightedRoundRobin>, the key of this inner Map is the value upstreamUrlvariable of each server node in this server list, the value object is WeightedRoundRobin, used to trace the rolling selection data about each server node. As to the implementation class for the Map object, we use ConcurrentHashMap of JUC, a hash table supporting full concurrency of retrievals and high expected concurrency for updates.
In the second level of the map, the embedded static class - WeighedRoundRobin of each node is thread-safe, implementing the weighted RoundRobin per bucket. The following is the code of the doselect() method of this class.
@Override
public Upstream doSelect(final List<Upstream> upstreamList, final String ip) {
String key = upstreamList.get(0).getUrl();
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);
if (Objects.isNull(map)) {
methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<>(16));
map = methodWeightMap.get(key);
}
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
Upstream selectedInvoker = null;
WeightedRoundRobin selectedWeightedRoundRobin = null;
for (Upstream upstream : upstreamList) {
String rKey = upstream.getUrl();
WeightedRoundRobin weightedRoundRobin = map.get(rKey);
int weight = getWeight(upstream);
if (Objects.isNull(weightedRoundRobin)) {
weightedRoundRobin = new WeightedRoundRobin();
weightedRoundRobin.setWeight(weight);
map.putIfAbsent(rKey, weightedRoundRobin);
}
if (weight != weightedRoundRobin.getWeight()) {
// weight changed.
weightedRoundRobin.setWeight(weight);
}
long cur = weightedRoundRobin.increaseCurrent();
weightedRoundRobin.setLastUpdate(now);
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = upstream;
selectedWeightedRoundRobin = weightedRoundRobin;
}
totalWeight += weight;
}
...... //erase the section which handles the time-out upstreams.
if (selectedInvoker != null) {
selectedWeightedRoundRobin.sel(totalWeight);
return selectedInvoker;
}
// should not happen here
return upstreamList.get(0);
}
For example we assume upstreamUrl values of three server nodes is: LIST = [upstream-20, upstream-50, upstream-30]. After a round of execution, the data in newly created methodWeightMap is as follows:
For the above example LIST, assumes the weight array is [20,50,30]. the following figure shows the value change and polling selection process of the current array in WeighedRoundRobin object.
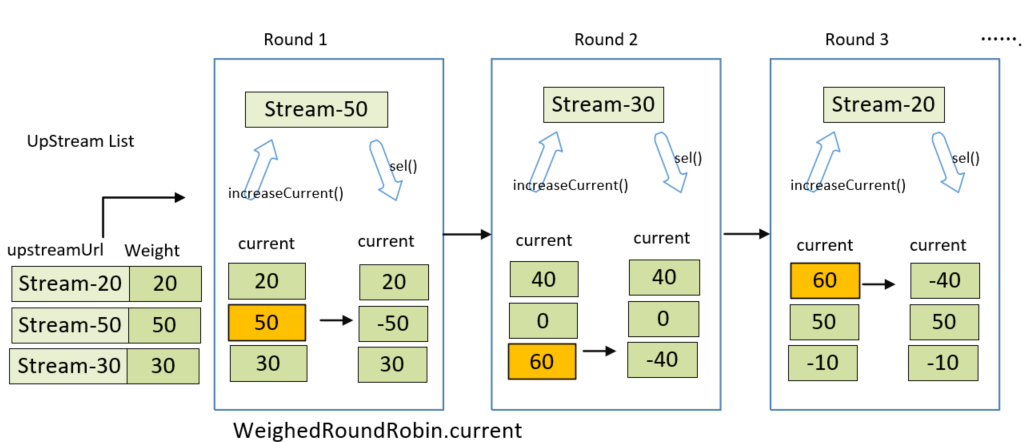
In each round, it will choose the server node with max current value.
- Round1:
- Traverse the server node list, initialize the
weightedRoundRobininstance of each server node or update theweightvalue of server nodes objectUpstream - Traverse the server node list, initialize the
weightedRoundRobininstance of each server node or update theweightvalue of server nodes objectUpstream - say, in this case, after traverse, the
currentarray of the node list changes to [20, 50,30],so according to rule, the node Stream-50 would be chosen, and then the static objectWeightedRoundRobinof Stream-50 executessel(-total), thecurrentarray is now [20,-50, 30].
- Traverse the server node list, initialize the
- Round 2: after traverse, the
currentarray should be [40,0,60], so the Stream-30 node would be chosen,currentarray is now [40,0,-40]. - Round 3: after traverse,
currentarray changes to [60,50,-10], Stream-20 would be chosen,andcurrentarray is now [-40,50,-10].
When there is any inconsistence or some server crashed, for example, the lists size does not match with the elements in map, it would copy and modify the element with lock mechanism, and remove the timeout server node, the data in Map updated. Following is the fault tolerance code segment.
if (!updateLock.get() && upstreamList.size() != map.size() && updateLock.compareAndSet(false, true)) {
try {
// copy -> modify -> update reference.
ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<>(map);
newMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > recyclePeriod);
methodWeightMap.put(key, newMap);
} finally {
updateLock.set(false);
}
}
if (Objects.nonNull(selectedInvoker)) {
selectedWeightedRoundRobin.sel(totalWeight);
return selectedInvoker;
}
// should not happen here.
return upstreamList.get(0);
LoadBalancerFactory
In this class, a static method calling LoadBalancer is provided, whereExtensionLoader is the entry point of Apache Shenyu SPI. That is to say, LoadBalancer module is configurable and extensible. The algorithm variable in this static method is the name enumeration type defined in LoadBalanceEnum.
/**
* Selector upstream.
*
* @param upstreamList the upstream list
* @param algorithm the loadBalance algorithm
* @param ip the ip
* @return the upstream
*/
public static Upstream selector(final List<Upstream> upstreamList, final String algorithm, final String ip) {
LoadBalancer loadBalance = ExtensionLoader.getExtensionLoader(LoadBalancer.class).getJoin(algorithm);
return loadBalance.select(upstreamList, ip);
}
Using of LoadBalancer module
In the above section, we describe the LoadBalancer SPI and three implementation classes. Let's take a look at how the LoadBalancer to be used in Apache Shenyu. DividePlugin is a plugin in Apache Shenyu responsible for routing http request. when enable to use this plugin, it will transfer traffic according to selection data and rule data, and deliver to next plugin downstream.
@Override
protected Mono<Void> doExecute(final ServerWebExchange exchange, final ShenyuPluginChain chain, final SelectorData selector, final RuleData rule) {
......
}
The type of second parameter of doExecute() is ShenyuPluginChain, which represents the execution chain of plugins. For details, see the mechanism of Apache Shenyu Plugins. The third one is SelectorData type, and the fourth is RuleData type working as the rule data.
In doExecute() of DividePlugin, first verify the size of header, content length, etc, then preparing for load balancing.
Following is a code fragment usingLoadBalancer in the doExecute() method:
// find the routing server node list
List<Upstream> upstreamList = UpstreamCacheManager.getInstance().findUpstreamListBySelectorId(selector.getId());
...
// the requested ip
String ip = Objects.requireNonNull(exchange.getRequest().getRemoteAddress()).getAddress().getHostAddress();
//calling the Utility class and invoke the LoadBalance processing.
Upstream upstream = LoadBalancerFactory.selector(upstreamList, ruleHandle.getLoadBalance(), ip);
In the above code, the output ofruleHandle.getLoadBalance() is the name variable defined in LoadBalanceEnum, that is random, hash, roundRobin, etc. It is very convenient to use LoadBalancer by LoadBalancerFactory. When adding more LoadBalancer implementing classes, the interface in plugin module will not be effect at all.
Summary
After reading through the code of LoadBalancer module, from the design perspective, it is concluded that this module has the following characteristics:
- Extensibility: Interface oriented design and implemented on
Apache Shenyu SPImechanism, it can be easily extended to other dynamic load balancing algorithms (for example, least connection, fastest mode, etc), and supports cluster processing. - Scalability: Every load balancing implementation, weighted Random, consistency Hashing and weighted
RoundRobincan well support increase or decrease cluster overall capacity. - More detailed design such as warm-up can bring better performance and obtain better overall stability.