AiTokenLimiter Plugin
Overview
The aiTokenLimiter plugin is used to track token consumption from LLM responses and enforce rate limiting via Redis. After each response, aiTokenLimiter calculates the number of tokens used and accumulates counts by user or business dimension. If the preset threshold is exceeded, subsequent requests can be rejected or throttled. Note that ShenYu’s rate limiting is typically implemented using Redis to store token buckets or sliding-window states; aiTokenLimiter likewise relies on Redis to record and check token usage. It is most commonly paired with aiProxy for token-based rate limiting.
Plugin Configuration
When configuring the plugin in the ShenYu admin console, you first create a Selector, then a Rule. A Selector matches request conditions (e.g., path, headers), while a Rule defines plugin parameters or forwarding targets. For more details, see Selector and Rule Management.
Key fields for aiTokenLimiter:
- Selector: Defines which requests to match. For example, set
Patternto/**to match all requests, or specify a particular route. - Rule: Configure plugin parameters:
timeWindowSeconds: Length of the rate-limiting window (in seconds). Within this window, the plugin tallies total token usage and compares it againsttokenLimit.keyName: Field name in the request used as the rate-limiting “dimension key,” in conjunction withaiTokenLimitType(e.g., HEADER, PARAMETER, COOKIE).tokenLimit: Maximum number of tokens allowed within the time window. The plugin counts downstream LLM completion tokens (the tokens consumed by generated content). Once this limit is exceeded, further requests receive an HTTP 429 response.
Example screenshots of aiTokenLimiter setup in the admin interface:
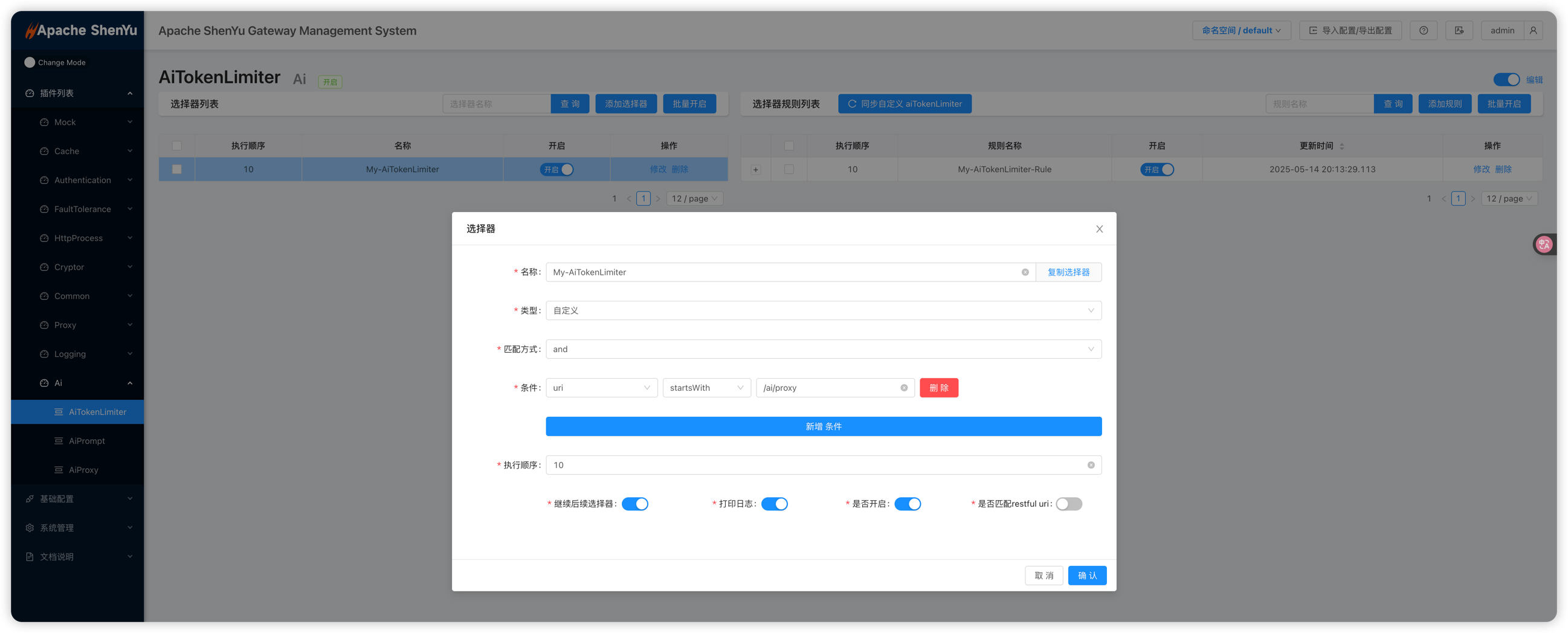
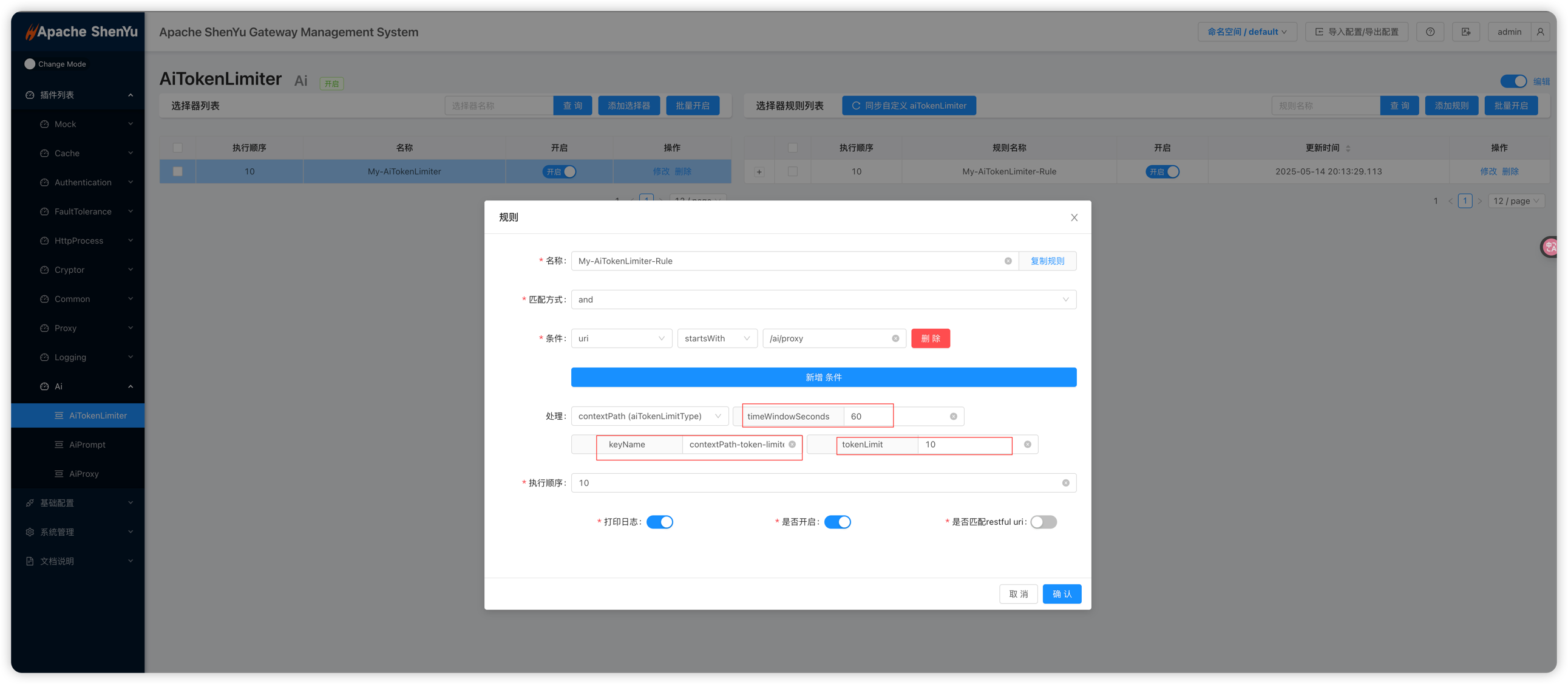
Note: The aiTokenLimiter plugin depends on aiProxy. In a typical flow, apply AiPrompt (if injecting a prompt), then AiTokenLimiter (for token counting/rate limiting), and finally AiProxy (to forward the request to the LLM). Ensure that AiTokenLimiter’s sort value is less than AiProxy and greater than AiPrompt in the “Plugin Management” list.
API Usage
With AiProxy and AiTokenLimiter enabled, send requests through the ShenYu gateway (e.g., via Postman) to proxy LLM calls:
curl --location --request POST 'http://localhost:9195/ai/proxy/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "我于杀戮之中盛放,亦如黎明中的花朵"
}
]
}'
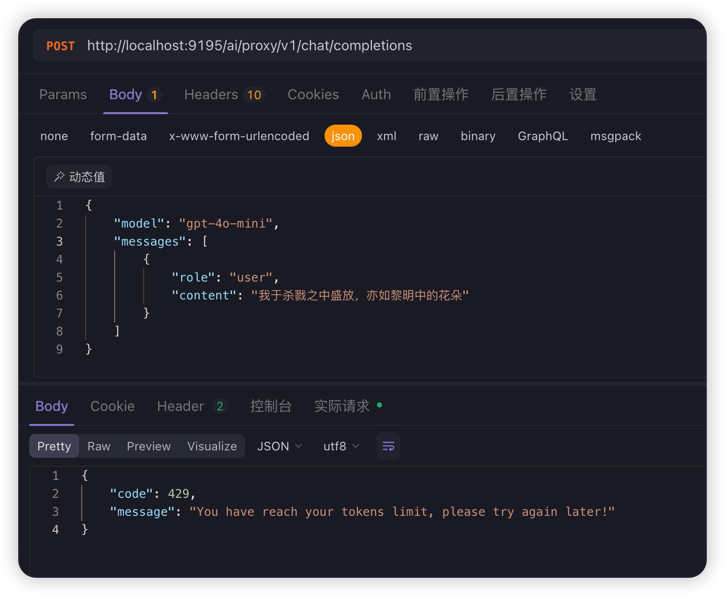
Example request (before rate limiting):
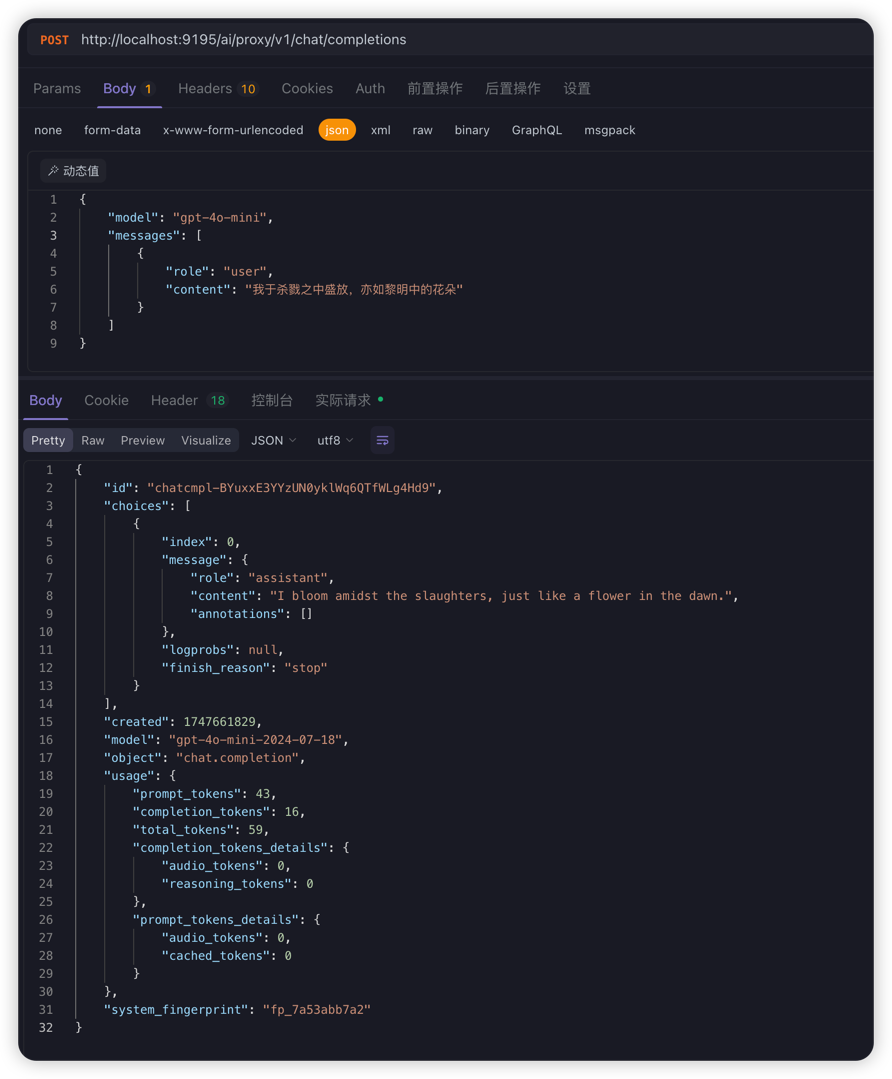
If you set tokenLimit=10 and make another request within 60 seconds, AiTokenLimiter will intercept it, return HTTP 429, and indicate that the token usage limit has been reached. Please try again later.
Example response (after rate limiting):