AiTokenLimiter插件
说明
aiTokenLimiter 插件用于统计来自 LLM 响应的 token 消耗,并基于 Redis 进行限流管理。每次响应返回后,aiTokenLimiter 会计算响应中使用的 token 数量,并按用户或业务维度累积计数。超过预设阈值时,可以拒绝或限制后续请求。需要注意的是,ShenYu 的限流实现通常基于 Redis 存储令牌桶或滑动窗口状态,aiTokenLimiter 也依赖 Redis 来记录和检查 token 用量。配合aiProxy进行使用, 主要用于token限流。
插件设置
在 ShenYu 管理界面配置插件时,需要先创建 Selector(选择器)再创建 Rule(规则)。Selector 通常用于匹配请求条件(如路径、Header 等),Rule 用于配置插件参数或转发目标。关于选择器和规则配置,请参考:选择器和规则管理。
使用aiTokenLimiter插件主要关注以下字段:
-
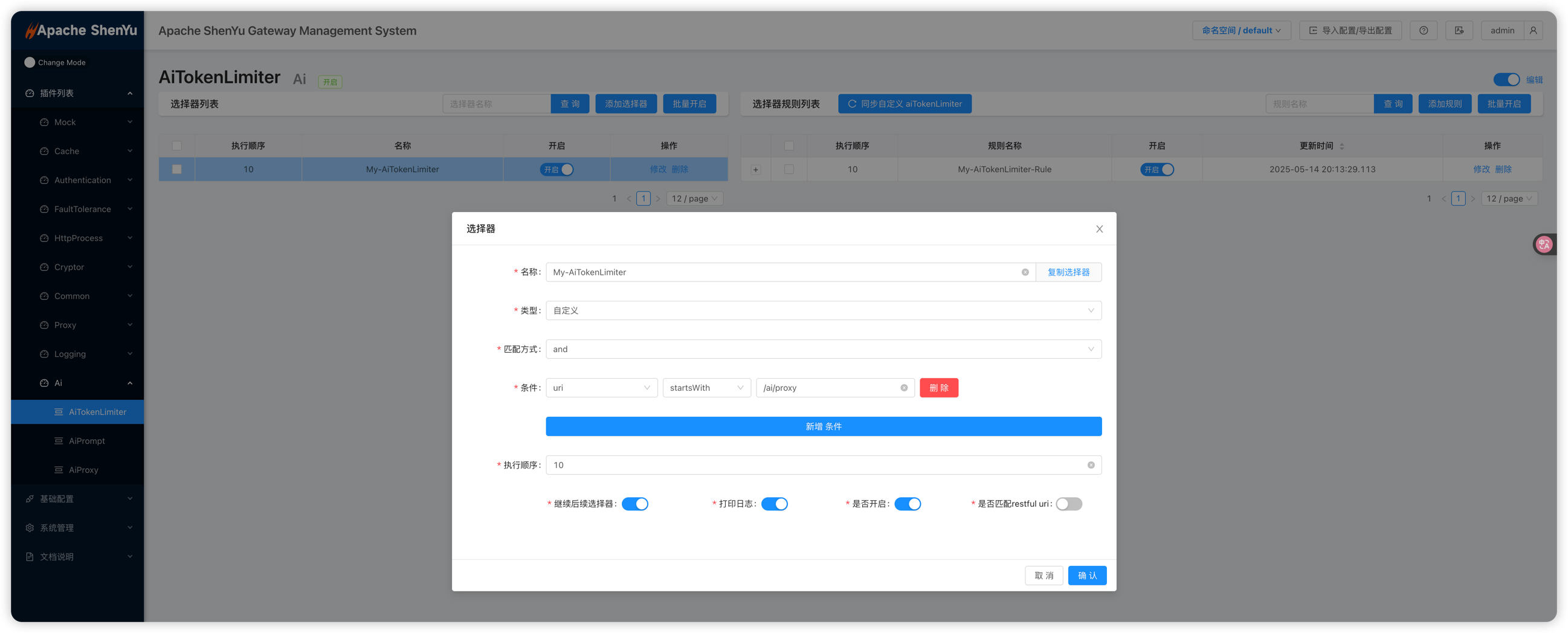
Selector: 选择器通常指定匹配的路径或请求特征。如可设置
Pattern为/**以匹配所有请求,或指定特定路由路径。 -
Rule: 在规则层面为各插件填写参数。各插件常见字段如下:
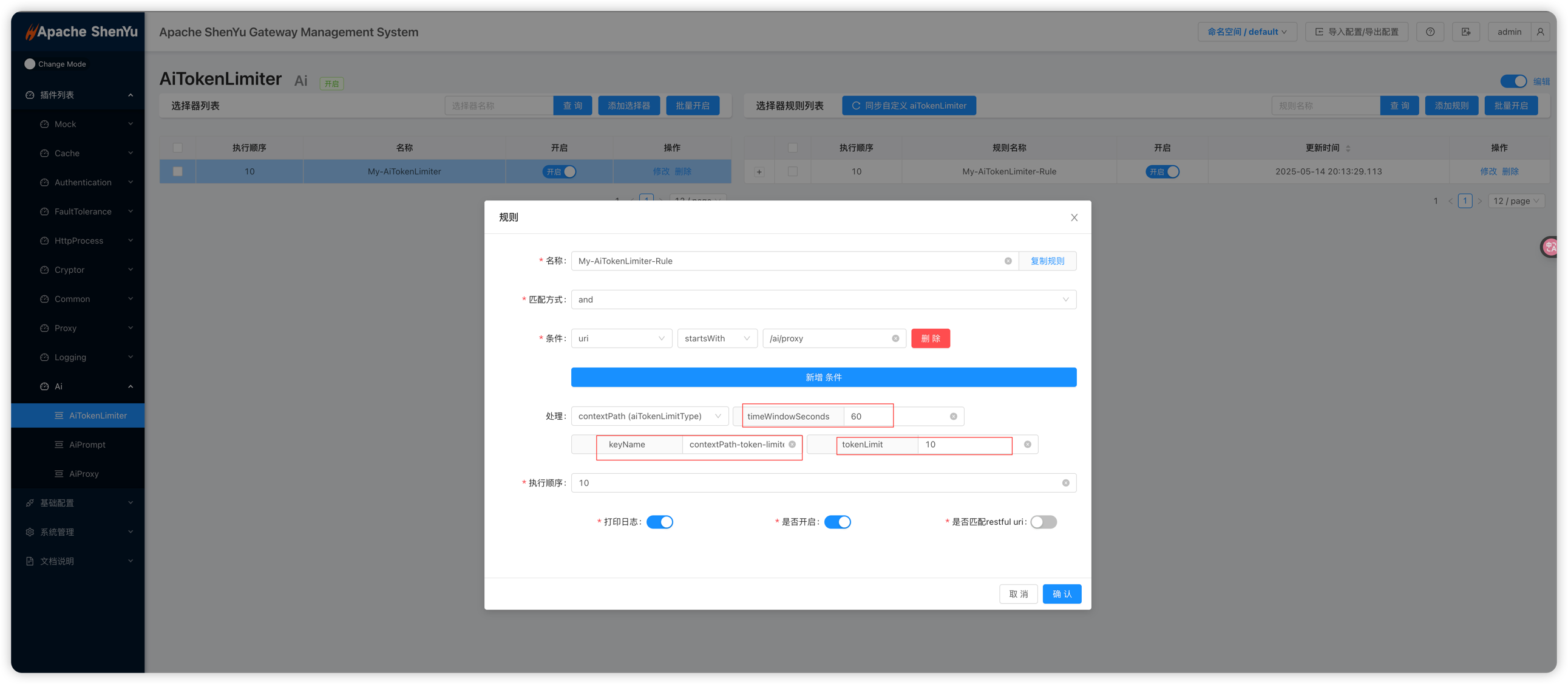
timeWindowSeconds:限流时间窗口的长度(单位:秒)。在该窗口期内,插件会统计累计的 Token 使用量,并与阈值(tokenLimit)比较。keyName:用于从请求中提取“限流维度键”的字段名。结合aiTokenLimitType(如 HEADER、PARAMETER、COOKIE)一起使用:;tokenLimit:时间窗口内允许的最大 Token 数量阈值。插件会统计下游 LLM 返回的 completion tokens(即模型生成内容消耗的 Token 数),累计超过此值时,将立即以 HTTP 429 拒绝后续请求。
以下给出aiTokenLimiter插件的配置示例截图在 (admin 界面):
注意:aiTokenLimiter插件依赖于aiProxy插件, 常的调用流程中,应先用 AiPrompt(如果需要注入 prompt),再用 AiTokenLimiter 做令牌统计/限流(如果需要token限流),最后由 AiProxy 将请求转发给 LLM 服务。确保在 “插件管理” 中,AiTokenLimiter 的 sort 值 小于 AiProxy,并 大于 AiPrompt。
API调用说明
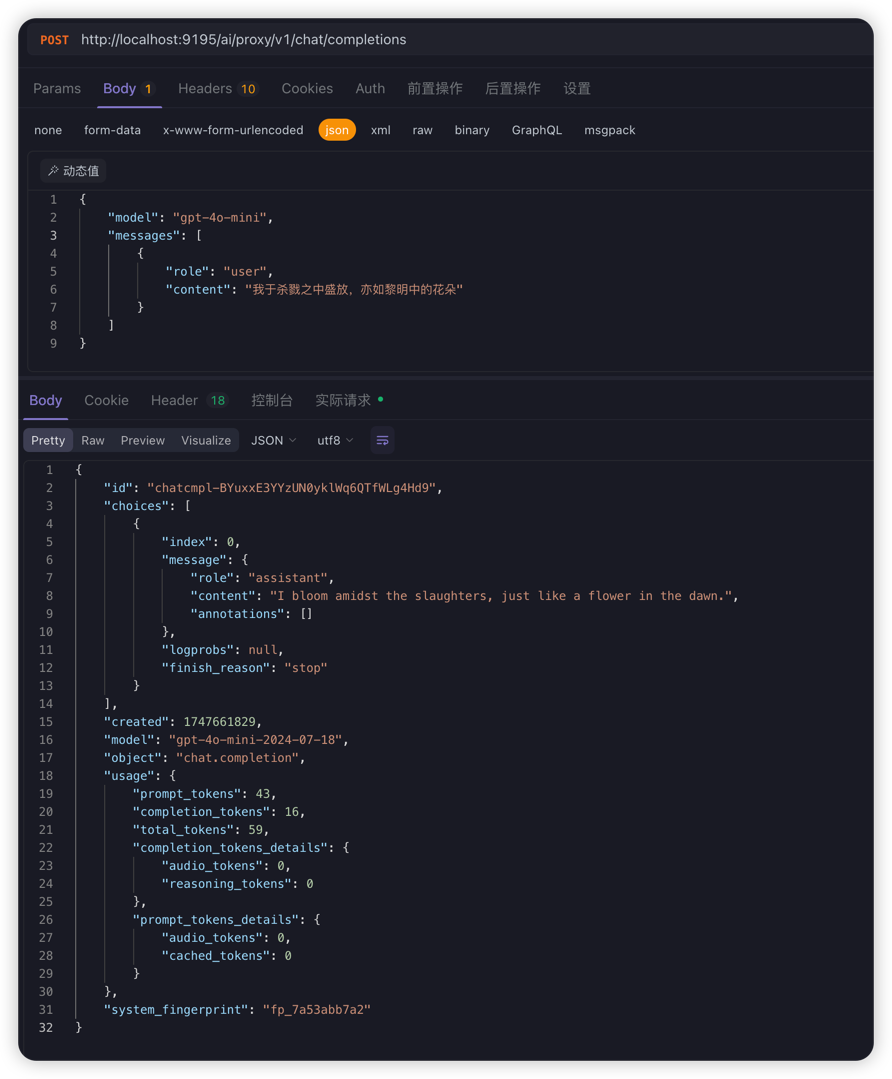
启用AiProxy和AiTokenLimiter插件后, 通过postman等工具请求shenyu网关, 即可通过网关代理获取LLM响应
curl --location --request POST 'http://localhost:9195/ai/proxy/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "我于杀戮之中盛放,亦如黎明中的花朵"
}
]
}'
示例截图
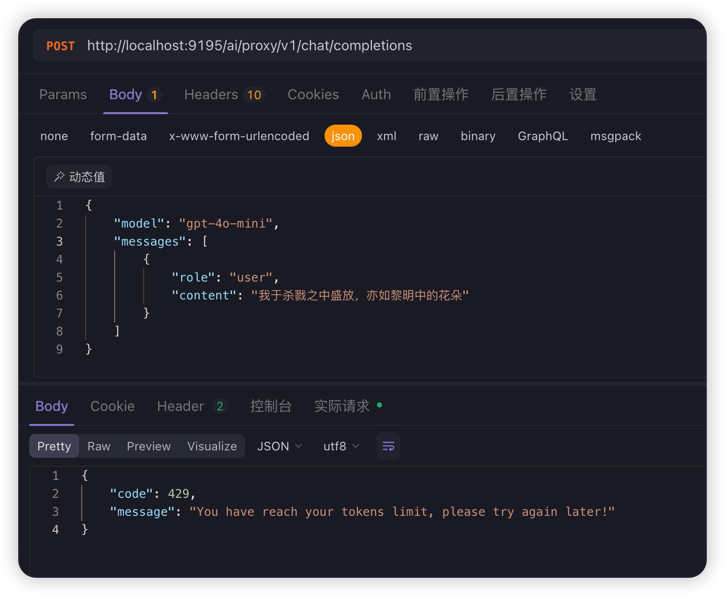
设置tokenLimit=10, 60s内再次调用, AiTokenLimiter会拦截请求, 返回429并提示已经达到token使用限制, 稍后重试。
示例截图