选择器和规则管理
本文档将介绍Apache ShenYu后台管理系统中选择器和规则的使用,关于选择器和规则的概念及设计请参考 流量控制。
请参考运维部署的内容,选择一种方式启动shenyu-admin。比如,通过 本地部署 启动Apache ShenYu后台管理系统。 启动成功后,可以直接访问 http://localhost:9095 ,默认用户名和密码分别为: admin 和 123456。
选择器
在插件列��表中展示了当前的所有插件,可以给每个插件添加选择器和规则:
例如,给divide插件添加选择器:
-
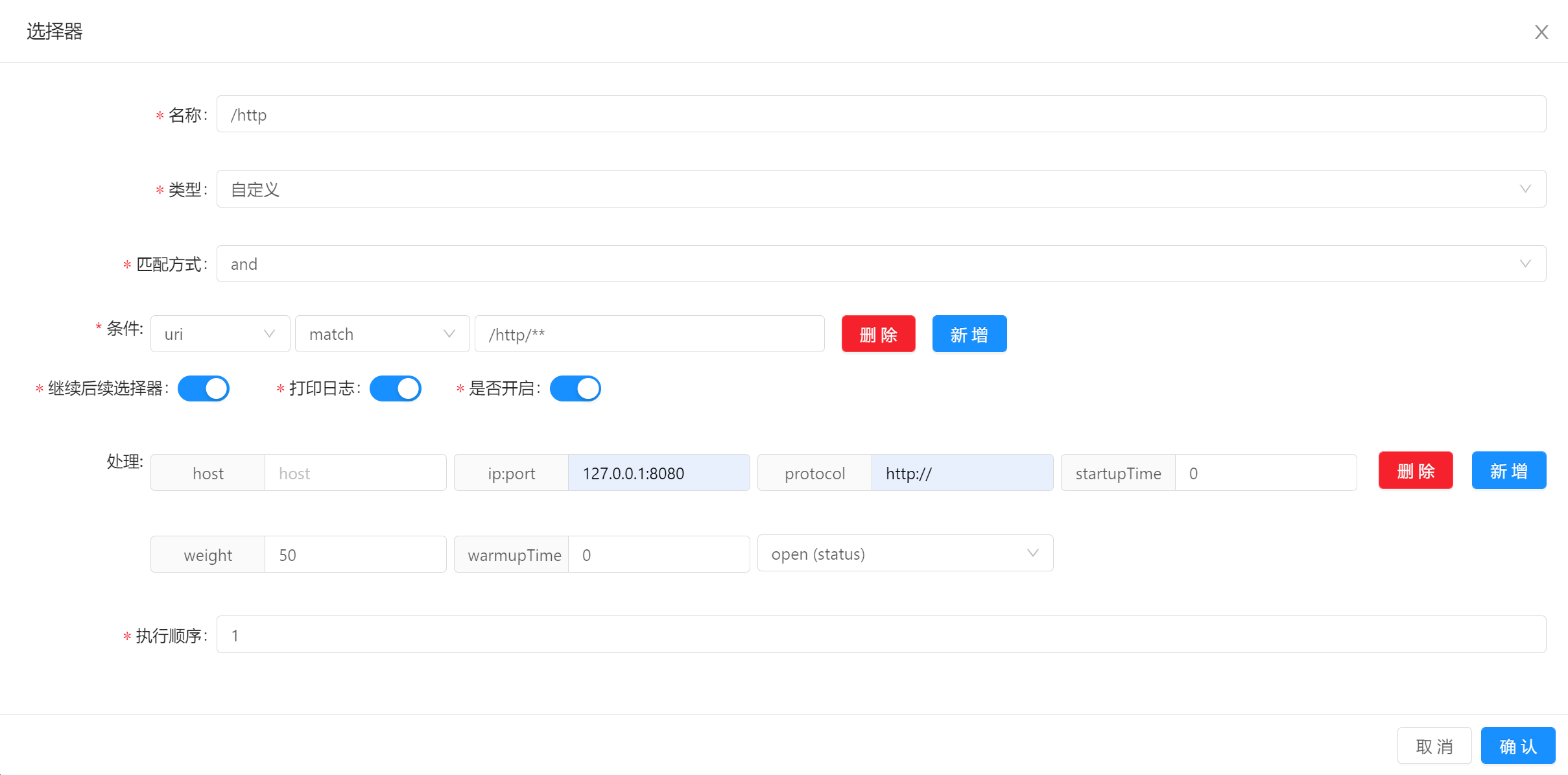
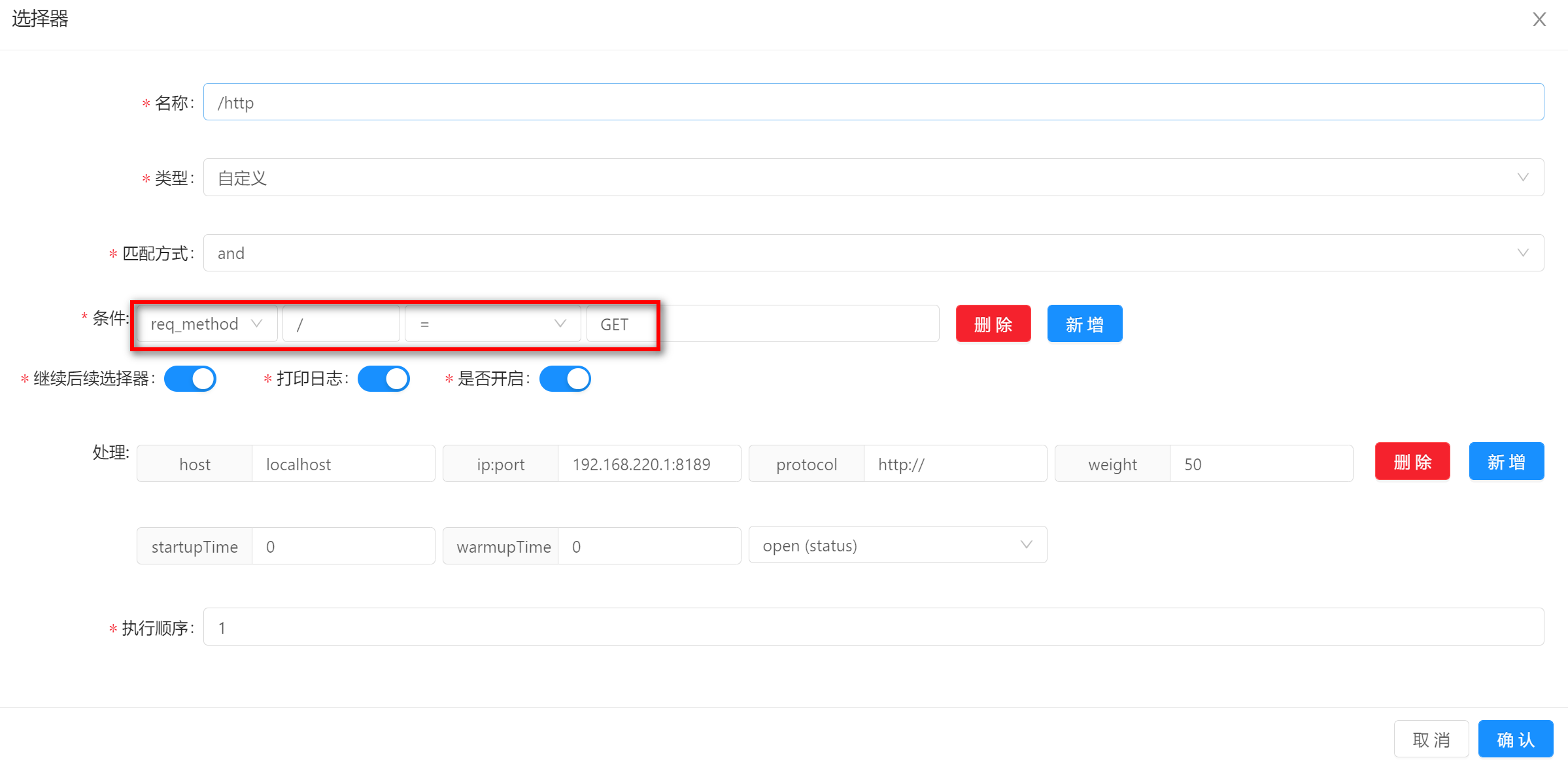
选择器详解:
- 名称:给选择器取一个名字。
- 类型:自定义流量(
custom flow) 或 全流量(full flow)。自定义流量就是请求会走下面的匹配方式与条件。全流量则不走。 - 匹配方式:
and或者or是指下面多个条件是按照 并(and) 还是 或(or) 的方式来组合。 - 条件:
uri:根据uri的方式来筛选流量,match的方式支持模糊匹配(/**)header:根据请求头里面的字段来筛选流量。query:根据uri的查询条件来进行筛选流量。ip:根据请求的真实ip来筛选流量。host:根据请求的真实host来筛选流量。post:根据请求上下文获取参数,不建议使用。cookie:根据请求的cookie来筛选流量。req_method:根据请求的方式来筛选流量。- 条件匹配:
match:模糊匹配,建议和uri条件搭配,支持restful风格的匹配。(/test/**)=:前后值相等,才能匹配。regEx:正则匹配,表示前面一个值去匹配后面的正则表达式。like:字符串模糊匹配。contains:请求包含指定的值,才能匹配。SpEl:SpEl表达式匹配。Groovy:通过Groovy脚本语言匹配。TimeBefore:指定时间之前。TimeAfter:指定时间之后。
- 继续后续选择器:后续选择器还是否执行。
- 是否开启:打开才会生效。
- 打印日志:打开时,当匹配上的时候,会打印匹配日志。
- 执行顺序:当多个选择器的时候,执行顺序小的优先执行,值越小优先级越高。
- 处理:即
handle字段,在 插件处理管理 中进行设置。作用是:当请求流量匹配上该选择器时,做什么样的处理操作。
-
上述图片中表示: 当请求的
uri前缀是/http,会转发到127.0.0.1:8080这个服务上。 -
选择器建议:可以通过设置
uri条件,match前缀(/contextPath)匹配,进行第一道流量筛选。
规则
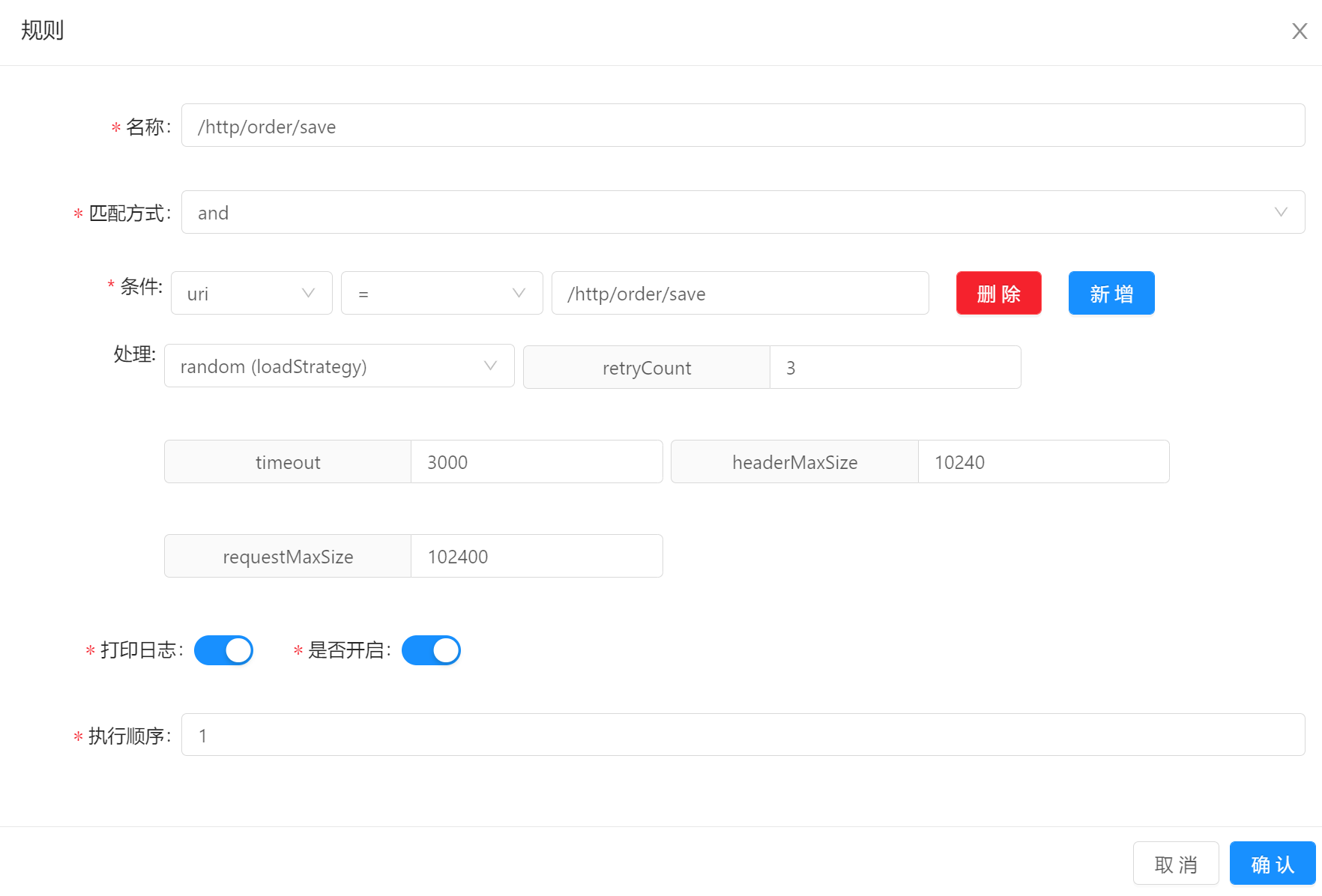
-
当流量经过选择器匹配成功之后,�会进入规则来进行最终的流量匹配。
-
规则是对流量最终执行逻辑的确认。
-
规则详解:
- 名称:给规则取一个名字。
- 匹配方式:
and或者or是指下面多个条件的组合方式。 - 条件:
uri:根据uri的方式来筛选流量,match的方式支持模糊匹配(/**)header:根据请求头里面的字段来筛选流量。query:根据uri的查询条件来进行筛选流量。ip:根据请求的真实ip来筛选流量。host:根据请求的真实host来筛选流量。post:不建议使用。cookie:根据请求的cookie来筛选流量。req_method:根据请求的req_method来筛选流量。- 条件匹配:
match:模糊匹配,建议和uri条件搭配,支持restful风格的匹配。(/test/**)=:前后值相等,才能匹配。regEx:正则匹配,表示前面一个值去匹配后面的正则表达式。like:字符串模糊匹配。contains:请求包含指定的值,才能匹配。SpEl:SpEl表达式匹配。Groovy:通过Groovy脚本语言匹配。TimeBefore:指定时间之前。TimeAfter:指定时间之后。
- ��是否开启:打开才会生效。
- 打印日志:打开时,当匹配上的时候,才会打印匹配日志。
- 执行顺序:当多个规则的时候,执行顺序小的优先执行。
- 处理:即
handle字段,在 插件处理管理 中进行设置。每个插件的规则处理不一样,具体请查看每个对应插件的处理。
-
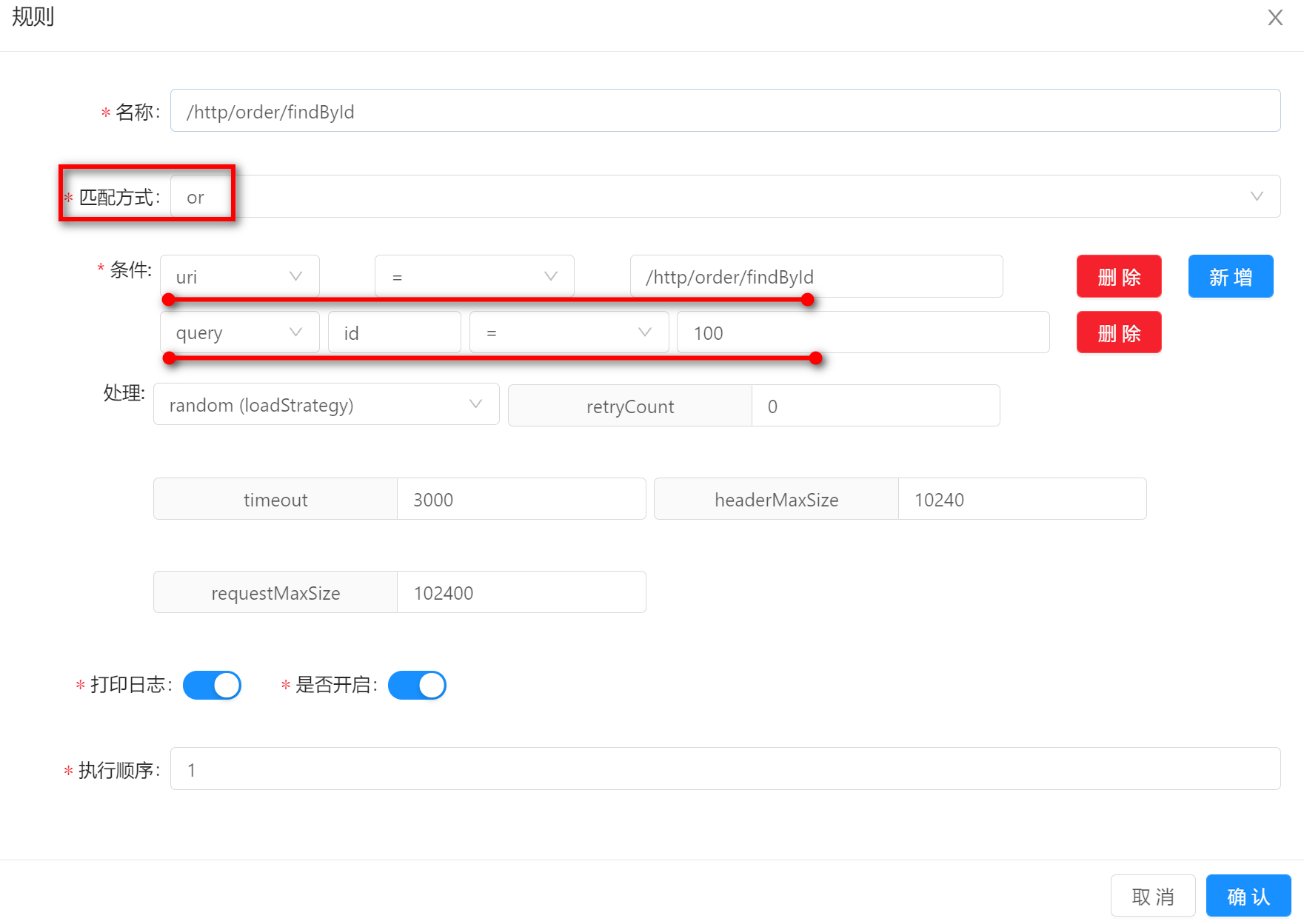
上图表示:当
uri等于/http/order/save的时候能够匹配上该规则,就会执行该规则中,负载策略是random,重试次数是3等处理操作。 -
规则建议:可以
uri条件,match最真实的uri路径,进行流量的最终筛选 。
联合选择器,我们来表述一下:当一个请求的 uri 为 /http/order/save,会通过 random 的方式,转发到 127.0.0.1:8080 机器上。
匹配方式
匹配方式是指在选择器或规则匹配时,多个条件之间的匹配方式,当前支持 and 和 or。
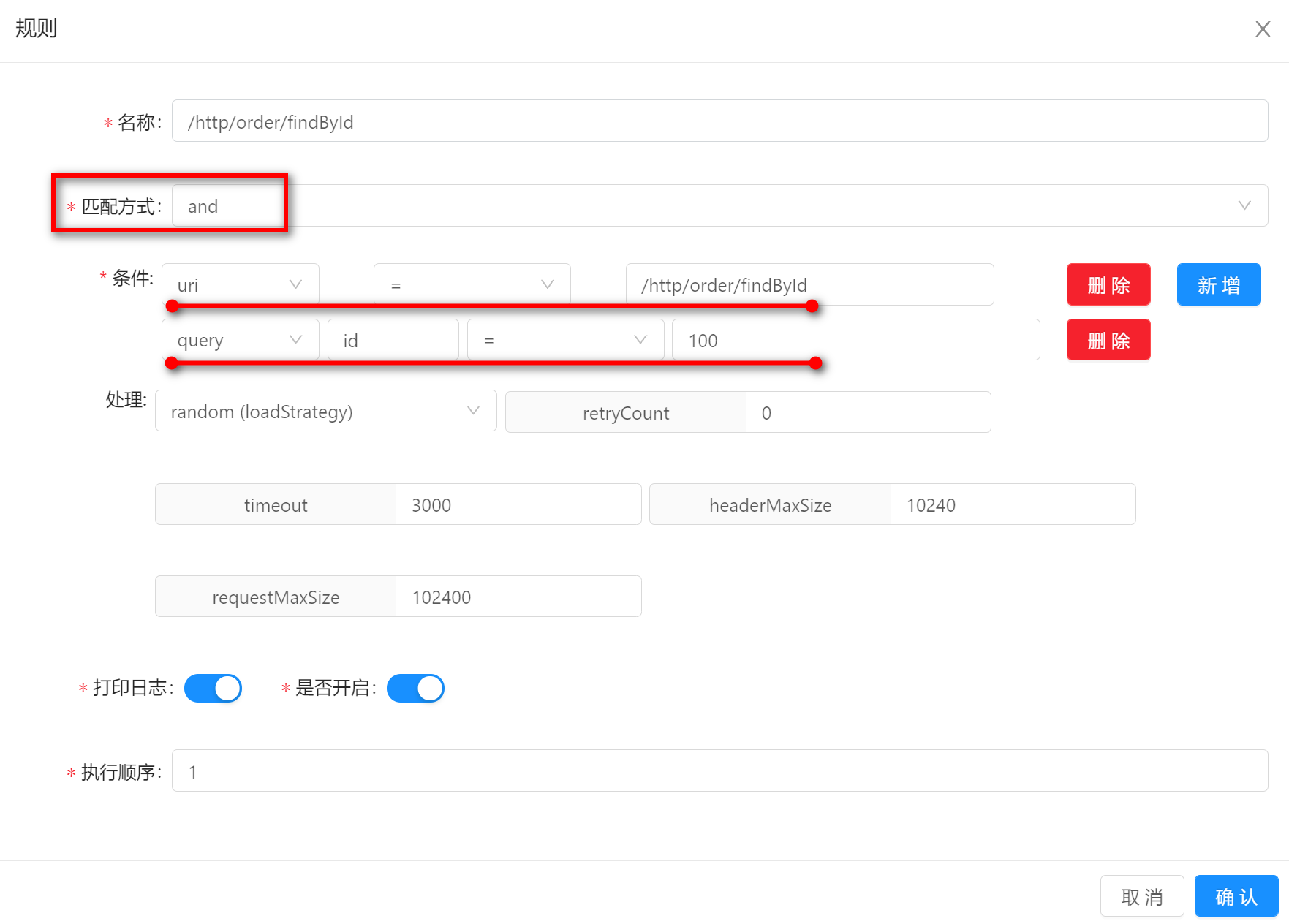
-
andand表示多个条件同时满足才能匹配上选择器或规则。下图中的示例表示,请求必须同时满足条件
uri = /http/order/findById和 条件id = 100才能匹配上该条规则。比如一个真实的请求
http://localhost:9195/http/order/findById?id=100能够同时满足上述两个条件,所以可以匹配上该条规则。
-
oror表示多个条件中满足一个就能匹配上选择器或规则。下图中的示例表示,请求满足条件
uri = /http/order/findById或者 条件id = 100就能匹配上该条规则。比如一个真实的请求
http://localhost:9195/http/order/findById?id=99能够满足上述第一个条件uri = /http/order/findById,所以也可以匹配上该条规则。
条件参数
对选择器和规则中的条件参数设置再次进行解释。假如下面是一个 HTTP 请求的请求头:
GET http://localhost:9195/http/order/findById?id=100
Accept: application/json
Cookie: shenyu=shenyu_cookie
MyHeader: custom-header
在ShenYu中可以通�过设置不同的条件参数从请求信息中获取真实数据。
- 如果条件参数是
uri,那么获取到的真实数据是/http/order/findById; - 如果条件参数是
header,字段名称是MyHeader,那么获取到的真实数据是custom-header; - 如果条件参数是
query,字段名称是id,那么获取到的真实数据是100; - 如果条件参数是
ip,那么获取到的真实数据0:0:0:0:0:0:0:1; - 如果条件参数是
host,那么获取到的真实数据是0:0:0:0:0:0:0:1; - 如果条件参数是
post,字段名称是contextPath,那么获取到的真实数据是/http; - 如果条件参数是
cookie,字段名称是shenyu,那么获取到的真实数据是shenyu_cookie; - 如果条件参数是
req_method,那么获取到的真实数据是GET。
-
uri(推荐)-
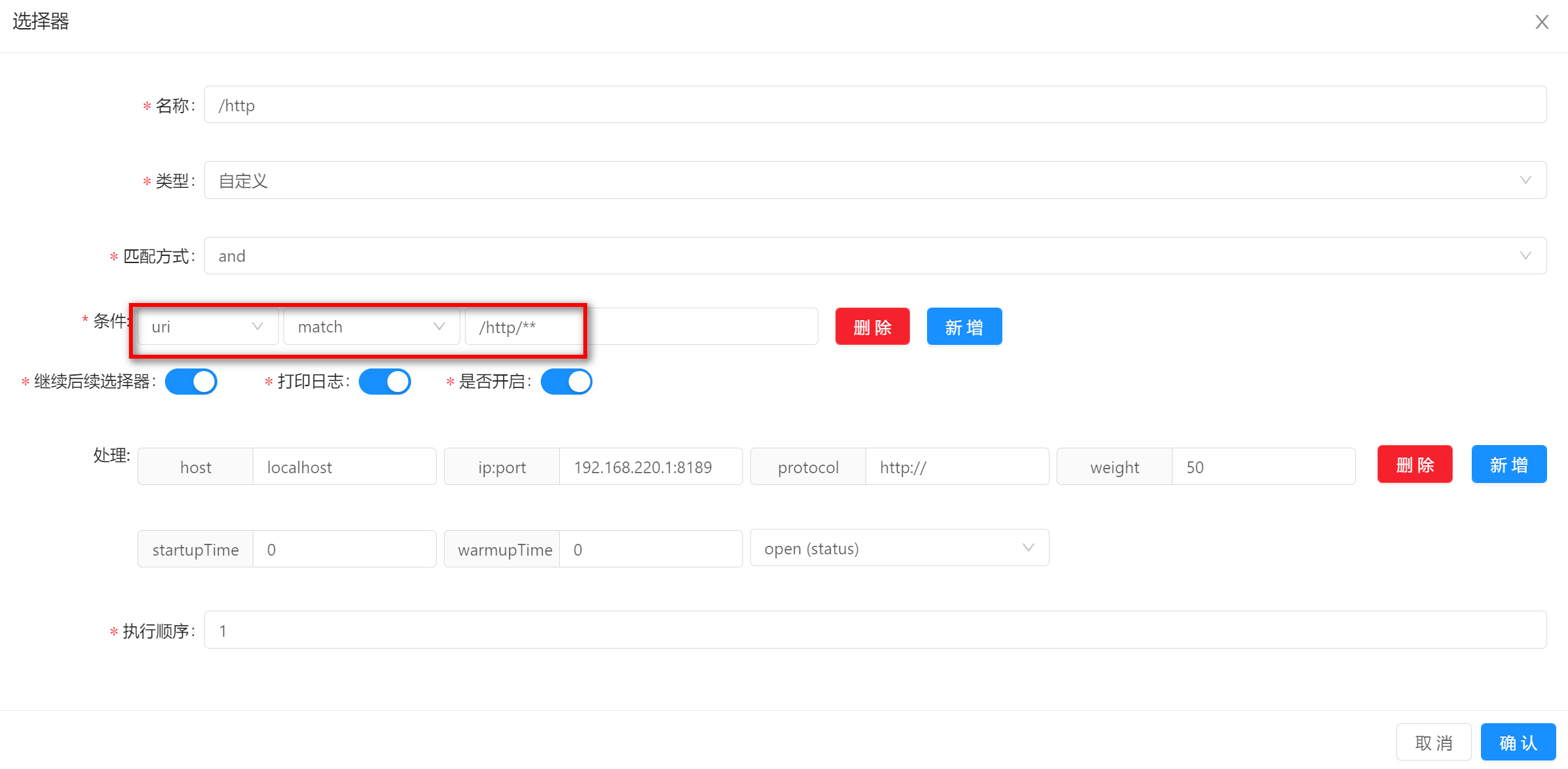
uri匹配是根据你请求路径中的uri来进行匹配,在接入网关的时候,前端几乎不用做任何更改。 -
当使用
match方式匹配时候,同springmvc模糊匹配原理相同。 -
在选择器中,推荐使用
uri中的前缀来进行匹配,而在规则中,则使用具体路径来进行匹配。 -
使用该匹配方式的时候,填写匹配字段的值,图中的示例是
/http/**。
-
-
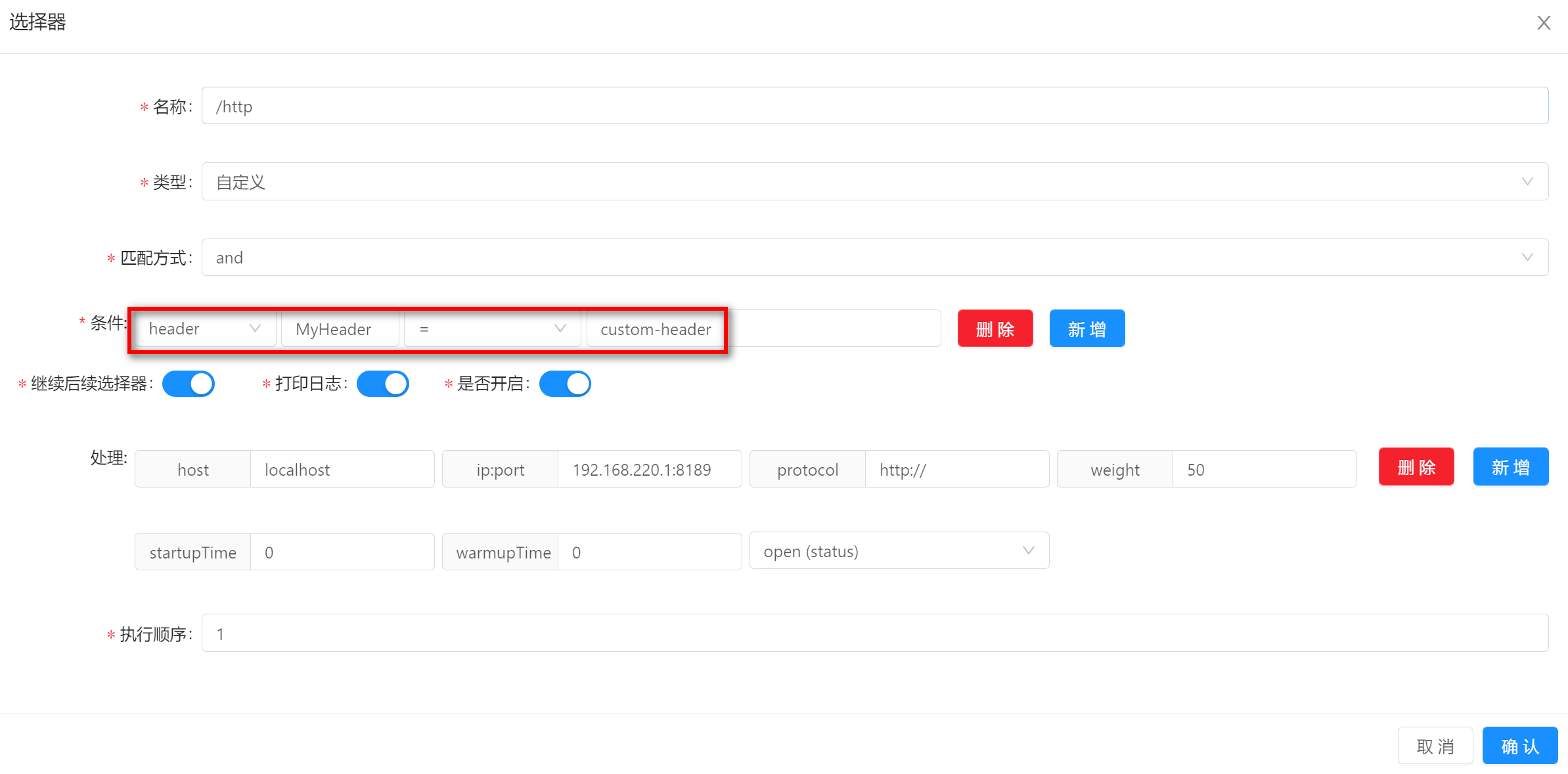
header-
header是根据你的http请求头中的字段值来匹配。 -
使用该匹配方式的时候,需要填写字段名称和字段值,图中的示例分别是
MyHeader和custom-header。
-
-
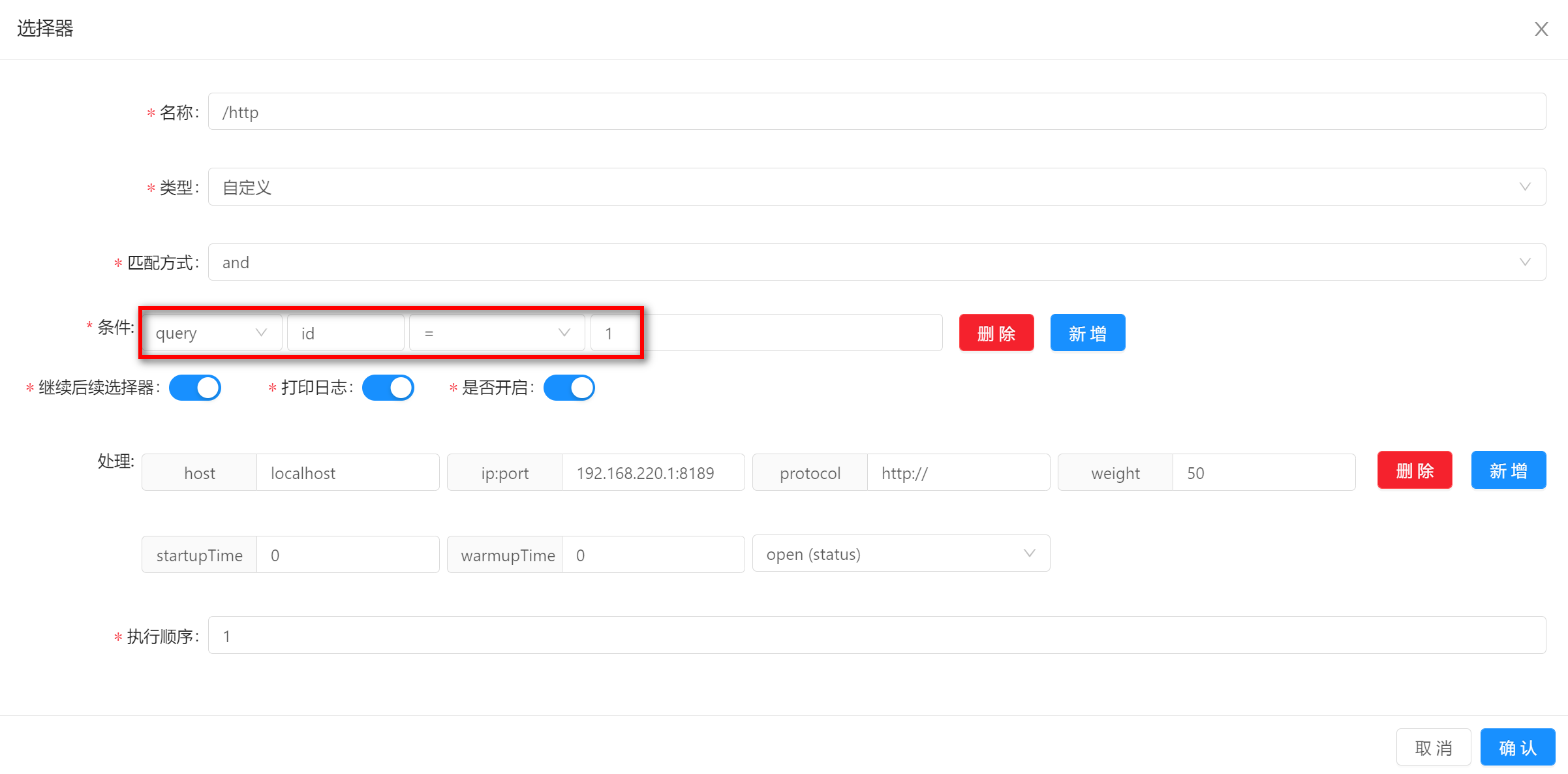
query-
这个是根据你的
uri中的查询参数来进行匹配,比如/test?id=1,那么可以选择该匹配方式。 -
使用该匹配方式的时候,需要填写字段名称和字段值,图中的示例分别是
id和1。
-
-
ip-
这个是根据
http调用方的ip来进行匹配。 -
尤其是在
waf插件里面,如果发现一个ip地址有攻击,可以新增一条匹配条件,填上该ip,拒绝该ip的访问。 -
如果在
Apache ShenYu前面使用了nginx代理,为了获取正确的ip,可以参考 自定义解析IP与Host 。 -
使用该匹配方式的时候,填写匹配字段的值,图中的示例是
192.168.236.75。
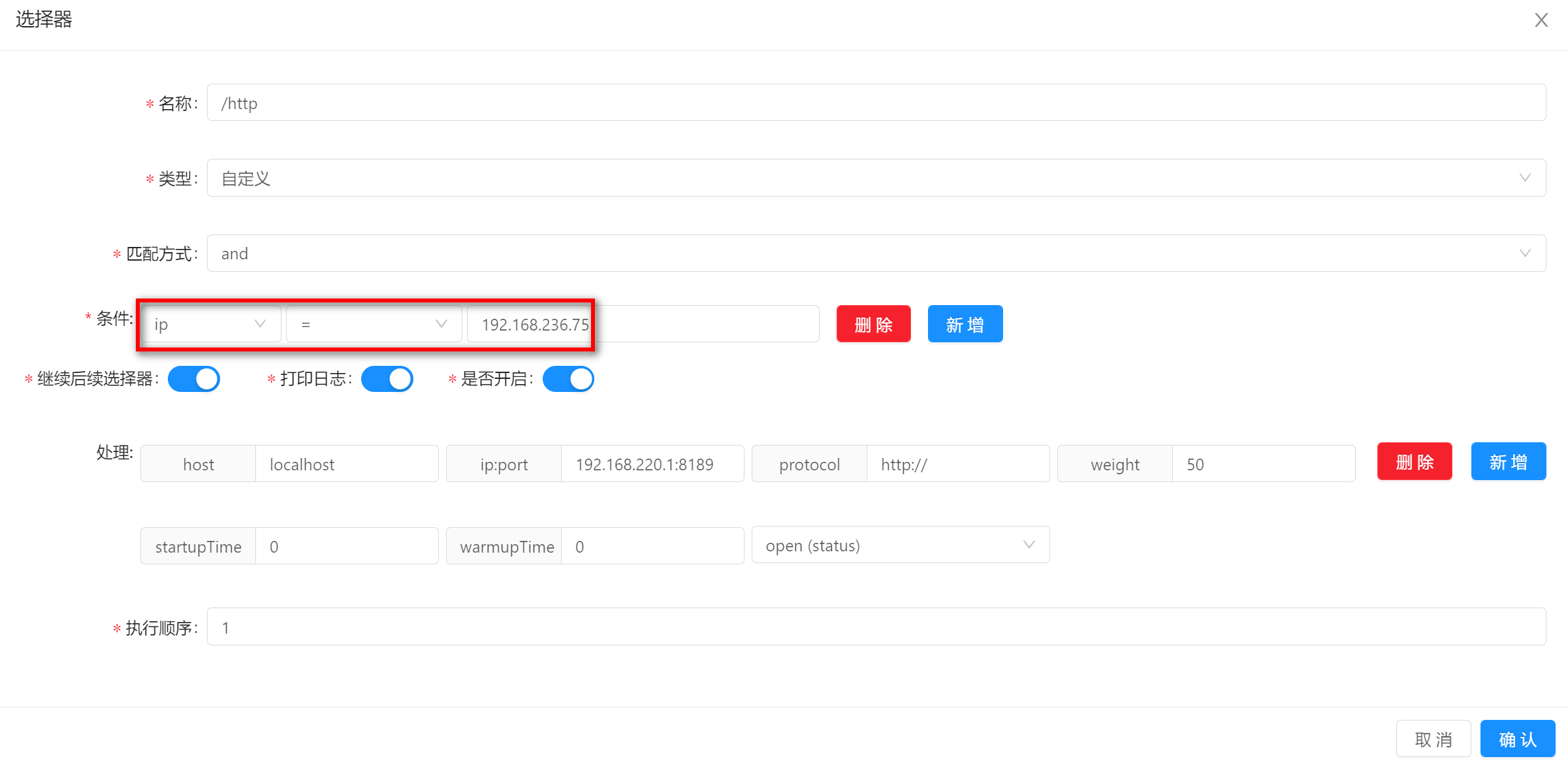
-
-
host-
这个是根据
http调用方的host来进行匹配。 -
尤其是在
waf插件里面,如果发现一个host地址有攻击,可以新增一条匹配条件,填上该host,拒绝该host的访问。 -
如果在
Apache ShenYu前面使用了nginx代理,为了获取正确的host,可以参考 自定义解析IP与Host 。 -
使用该匹配方式的时候,填写匹配字段的值,图中的示例是
localhost。
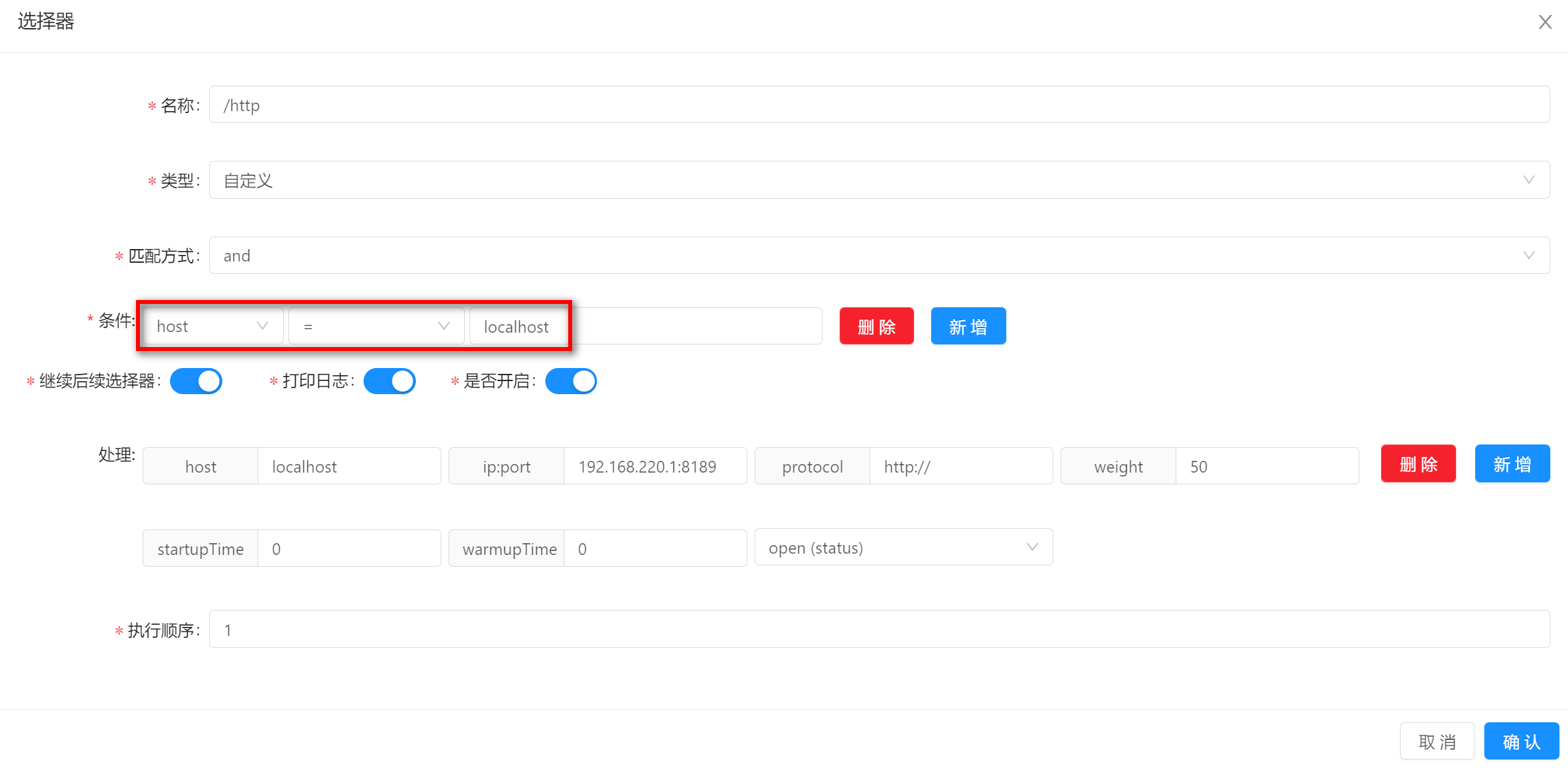
-
-
post-
从请求上下文(
org.apache.shenyu.plugin.api.context.ShenyuContext)中获取条件参数,需要通过反射获取字段的值,不推荐使用此方式。 -
使用该匹配方式的时候,需要填写字段名称和字段值,图中的示例分别是
contextPath和/http。
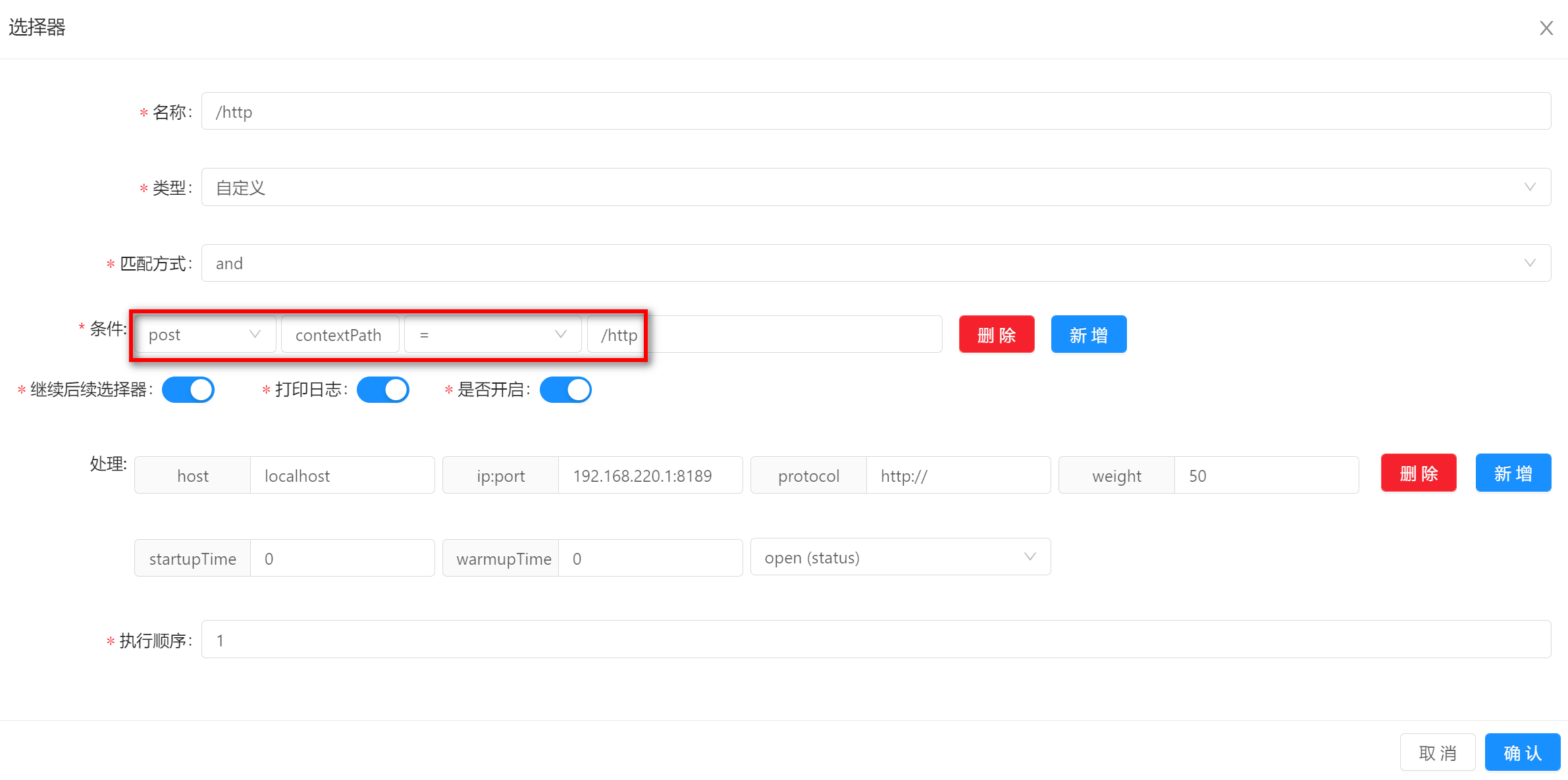
-
-
cookie-
这个是根据
http调用方的请求头中Cookie作为条件参数进行匹配。 -
使用该匹配方式的时候,需要填写字段名称和字段值,图中的示例分别是
shenyu和shenyu_cookie。
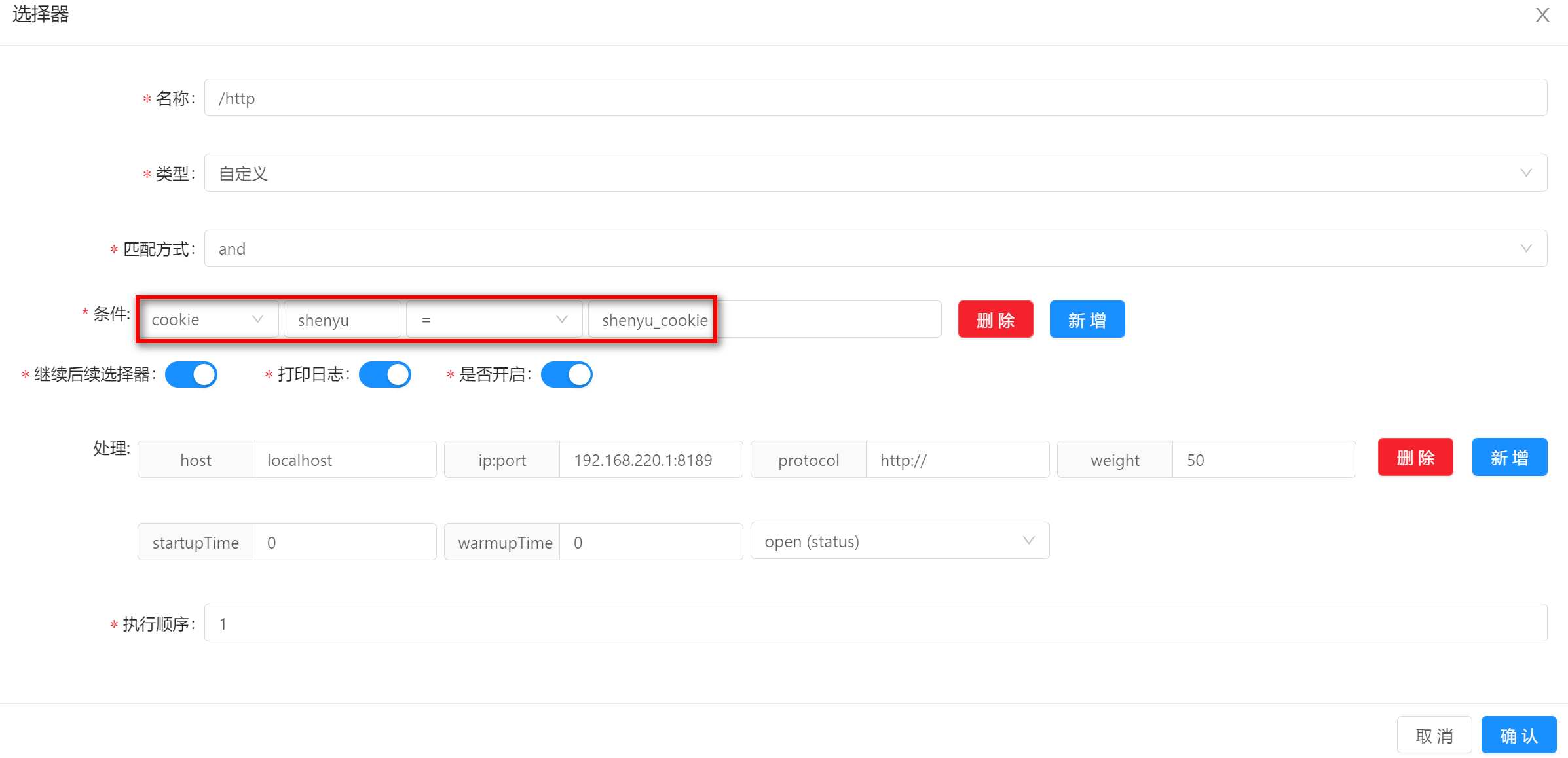
-
-
req_method-
这个是根据
http调用方的请求形式来进行匹配,比如GET、POST等。 -
使用该匹配方式的时候,填写匹配字段的值,图中的示例是
GET。
-
如果想更深入理解条件参数的获取,请阅读相关源码,包名是org.apache.shenyu.plugin.base.condition.data:
| 条件参数 | 源码类 |
|---|---|
uri | URIParameterData |
header | HeaderParameterData |
query | QueryParameterData |
ip | IpParameterData |
host | HostParameterData |
post | PostParameterData |
cookie | CookieParameterData |
req_method | RequestMethodParameterData |
条件匹配策略
通过条件参数能够获取到请求的真实数据。真实数据如何匹配上选择器或规则预设的条件数据,是通过条件匹配策略来实现。
-
matchmatch的方式支持模糊匹配(/**)。假如你的选择器条件设置如下,那么请求/http/order/findById就可以匹配上。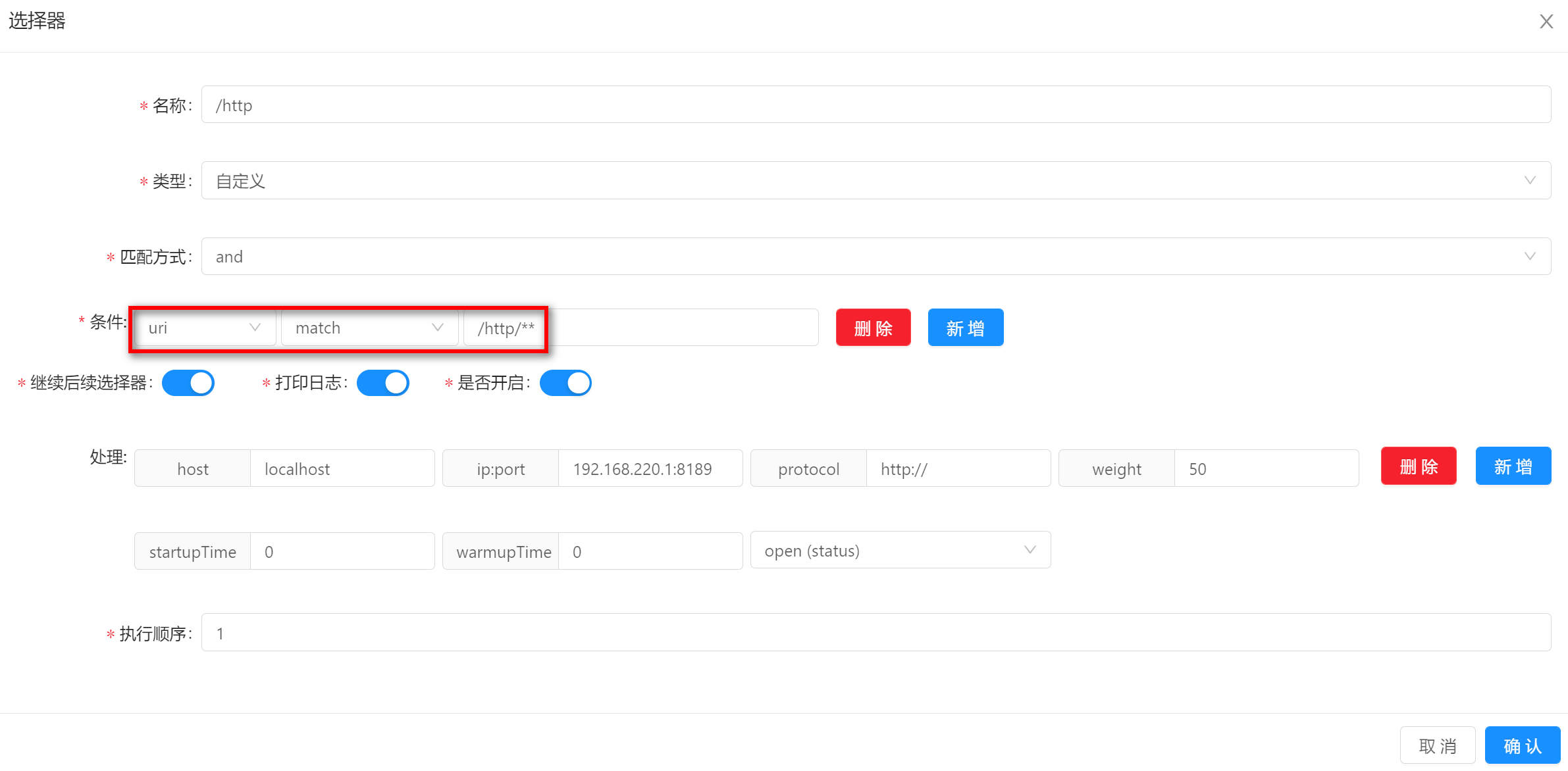
-
==的方式表示请求的真实数据和预设的条件数据相等。假如你的选择器条件设置如下:请求uri等于/http/order/findById,那么请求/http/order/findById?id=1就可以匹配上。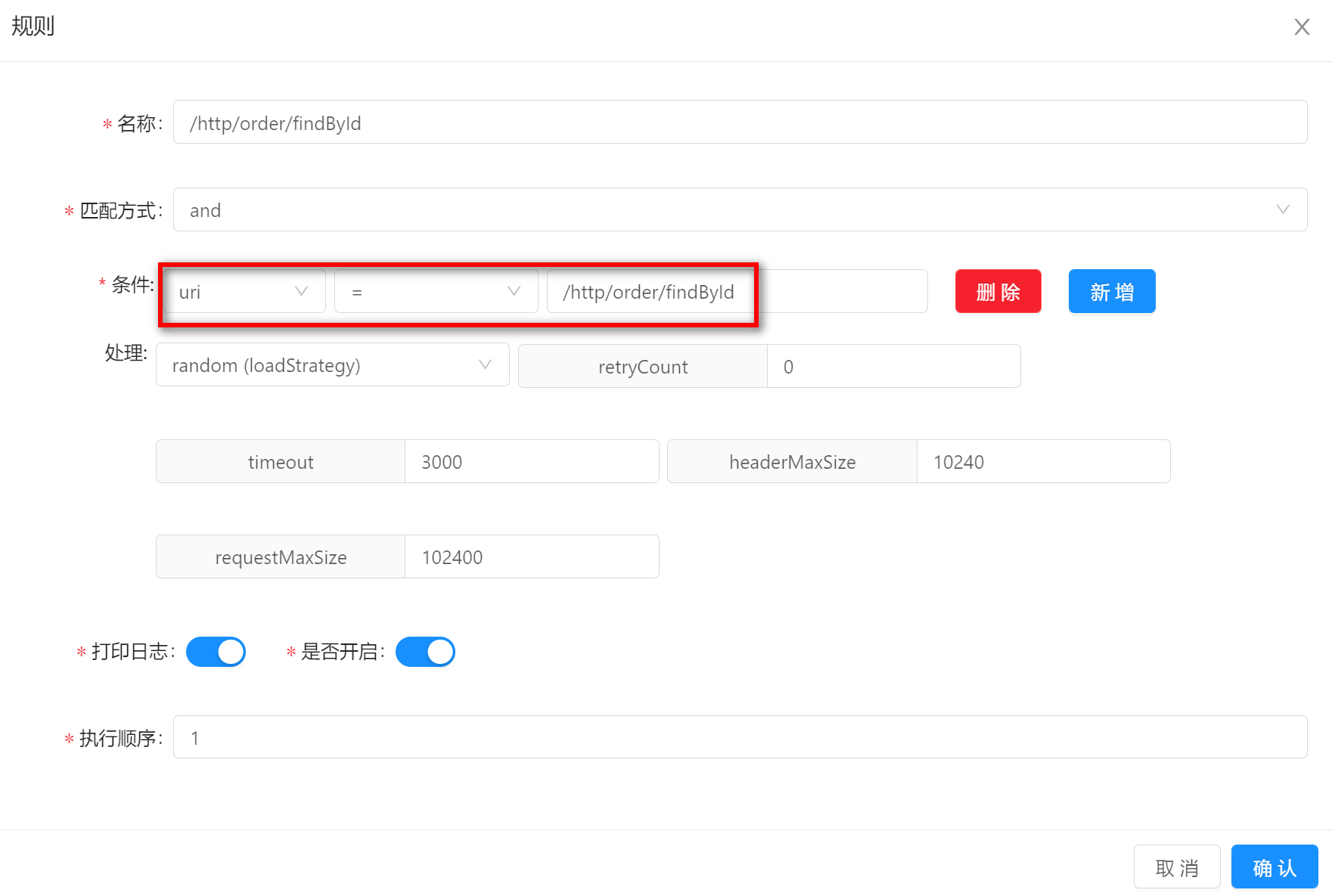
-
regexregex的方式表示请求的真实数据能够满足预设条件的正则表达式才能匹配成功。假如你的规则条件设置如下:请求参数中包含id,并且是3位数字。那么请求/http/order/findById?id=900就可以匹配上。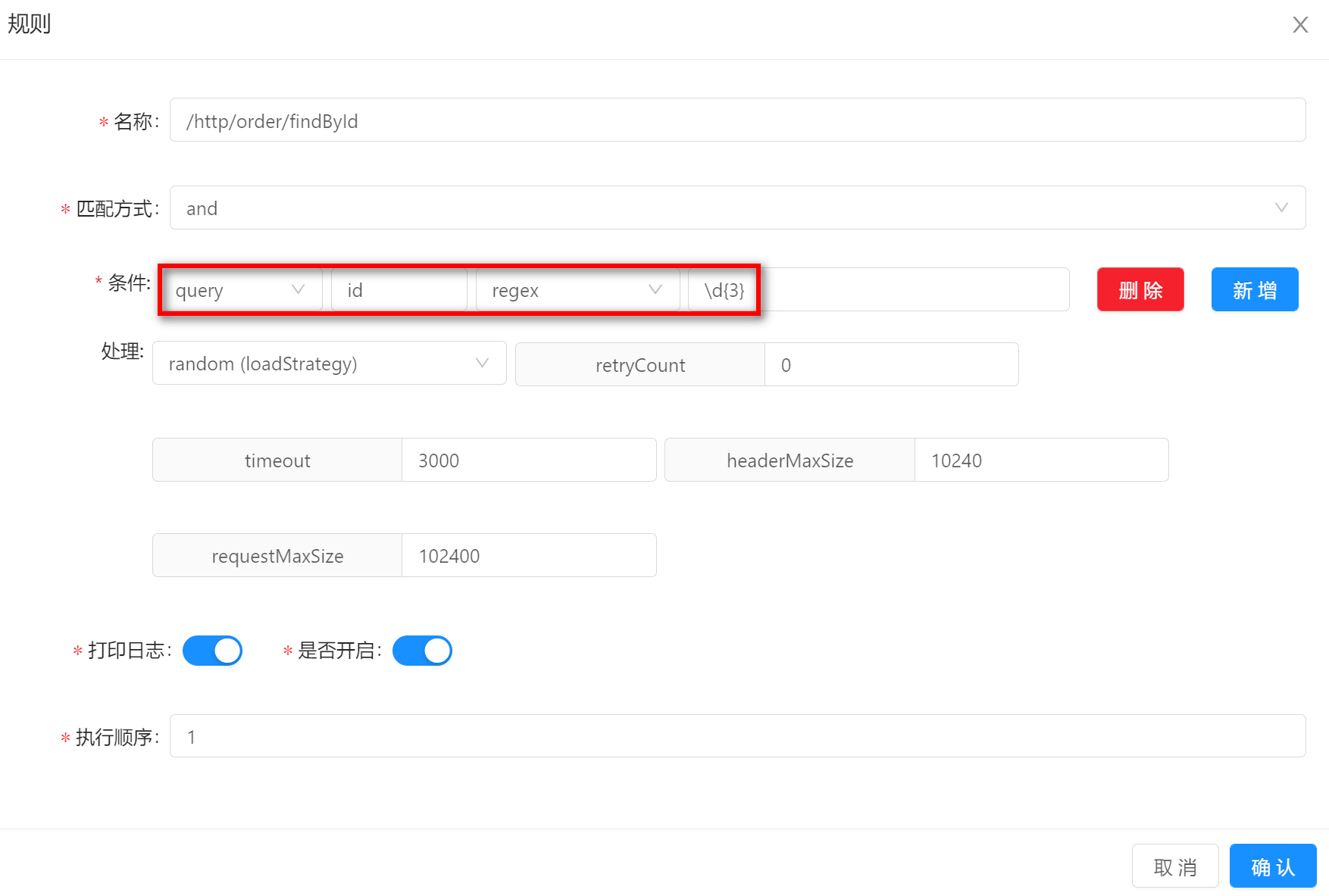
-
containscontains的方式表示请求的真实数据包含预设的条件数据。假如你的规则条件设置如下:请求uri中包含findById。那么请求/http/order/findById?id=1就可以匹配上。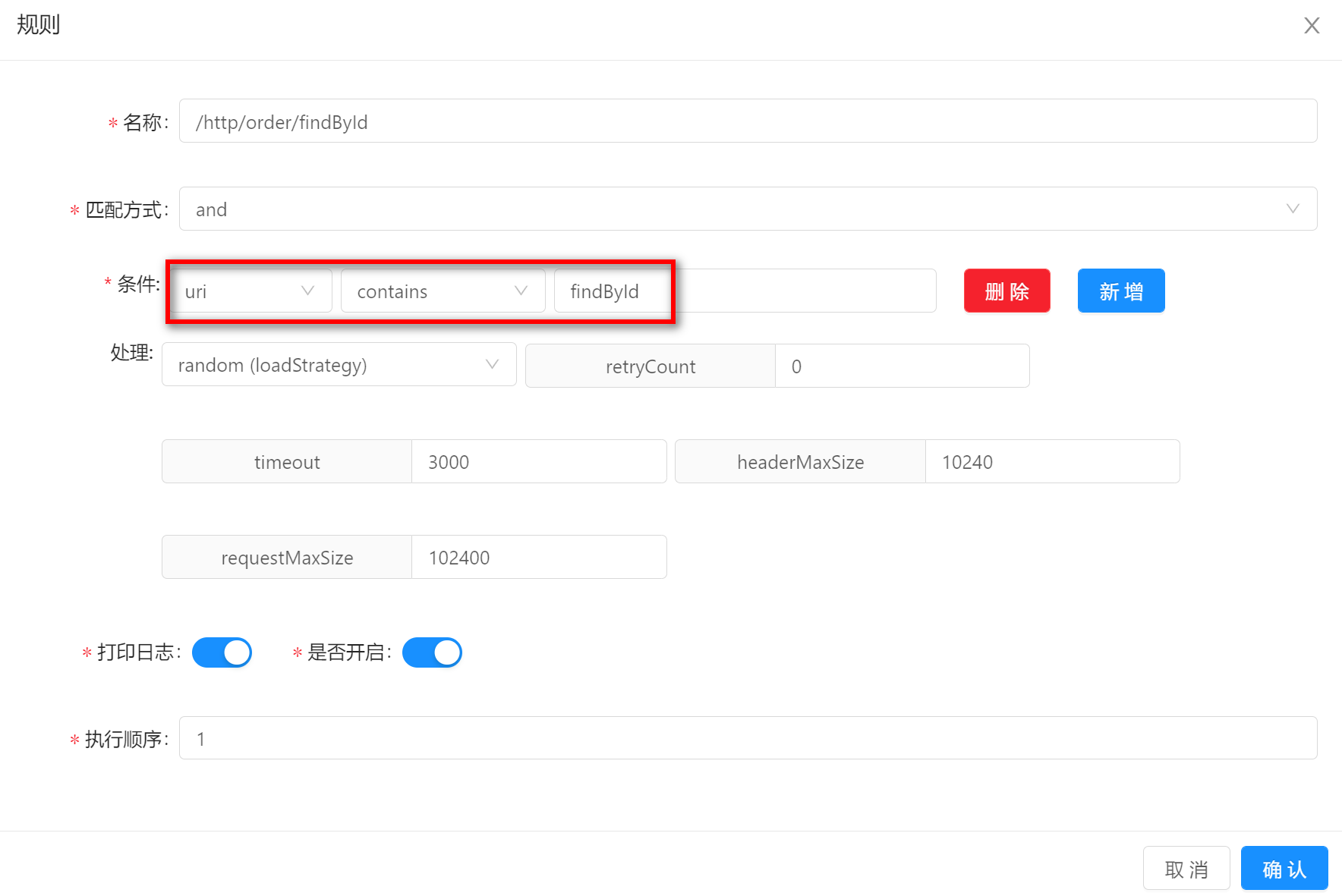
-
SpELSpEL的方式表示请求的真实数据能够满足预设的SpEL表达式。假如你的规则条件设置如下:请求参数中包含id,并且id大于100。那么请求/http/order/findById?id=101就可以匹配上。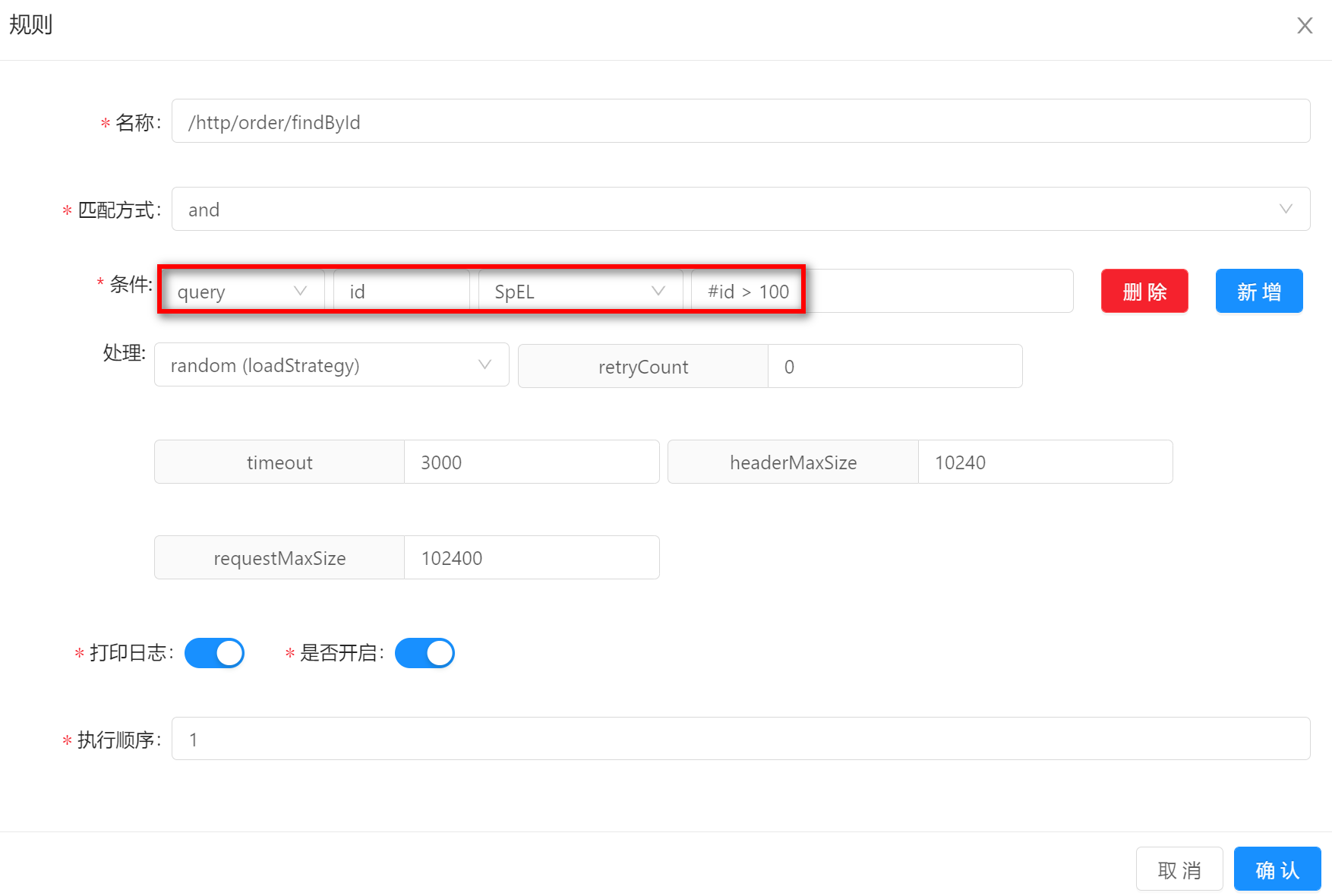
-
GroovyGroovy的方式表示请求的真实数据能够满足预设的Groovy表达式。假如你的规则条件设置如下:请求参数中包含id,并且id等100。那么请求/http/order/findById?id=100就可以匹配上。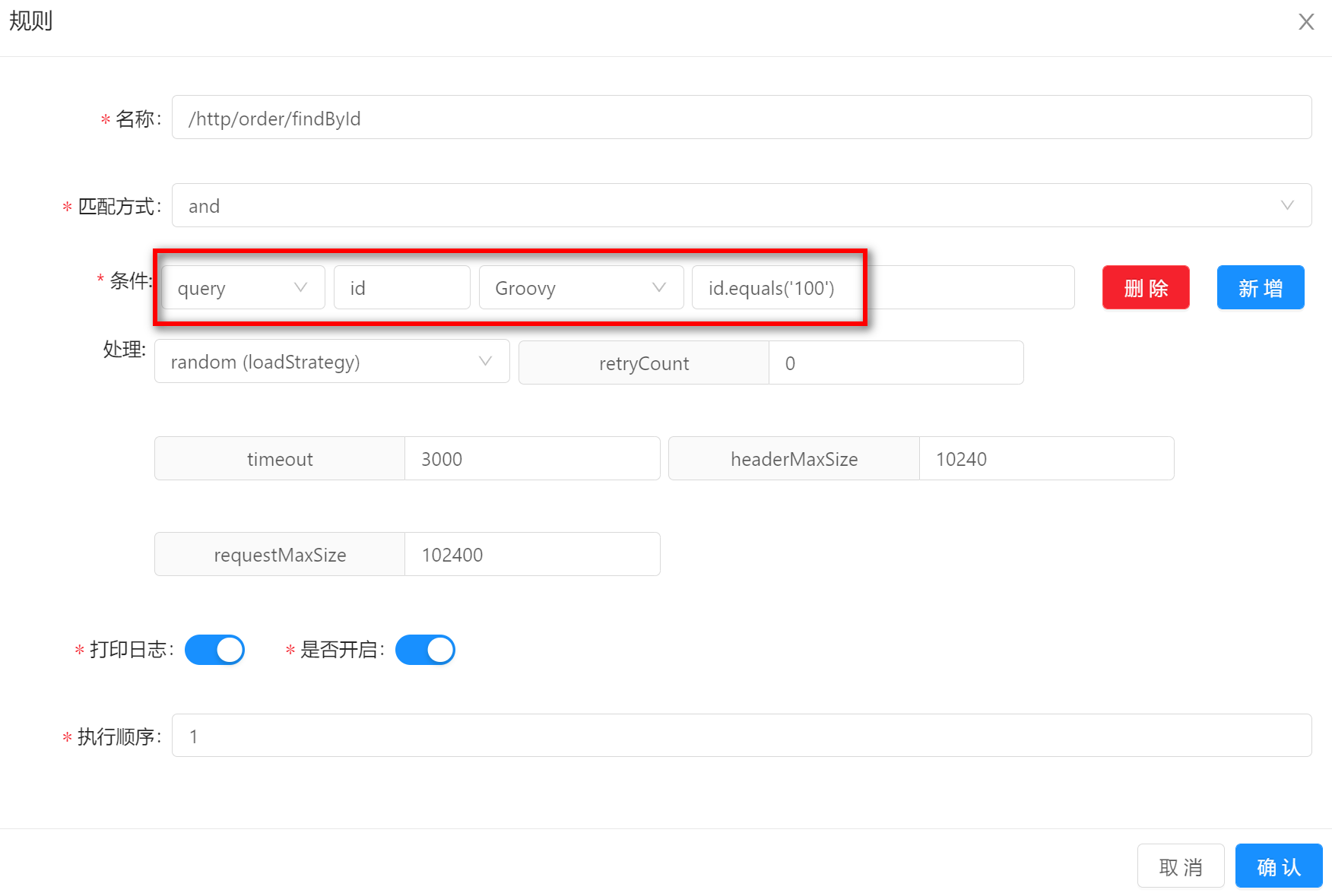
-
TimeBeforeTimeBefore的方式表示请求时间在预设的条件时间之前才能匹配成功。假如你的规则条件设置如下:请求参数中包含date,并且date小于2021-09-26 06:12:10。那么请求/http/order/findById?id=100&date=2021-09-22 06:12:10就可以匹配上。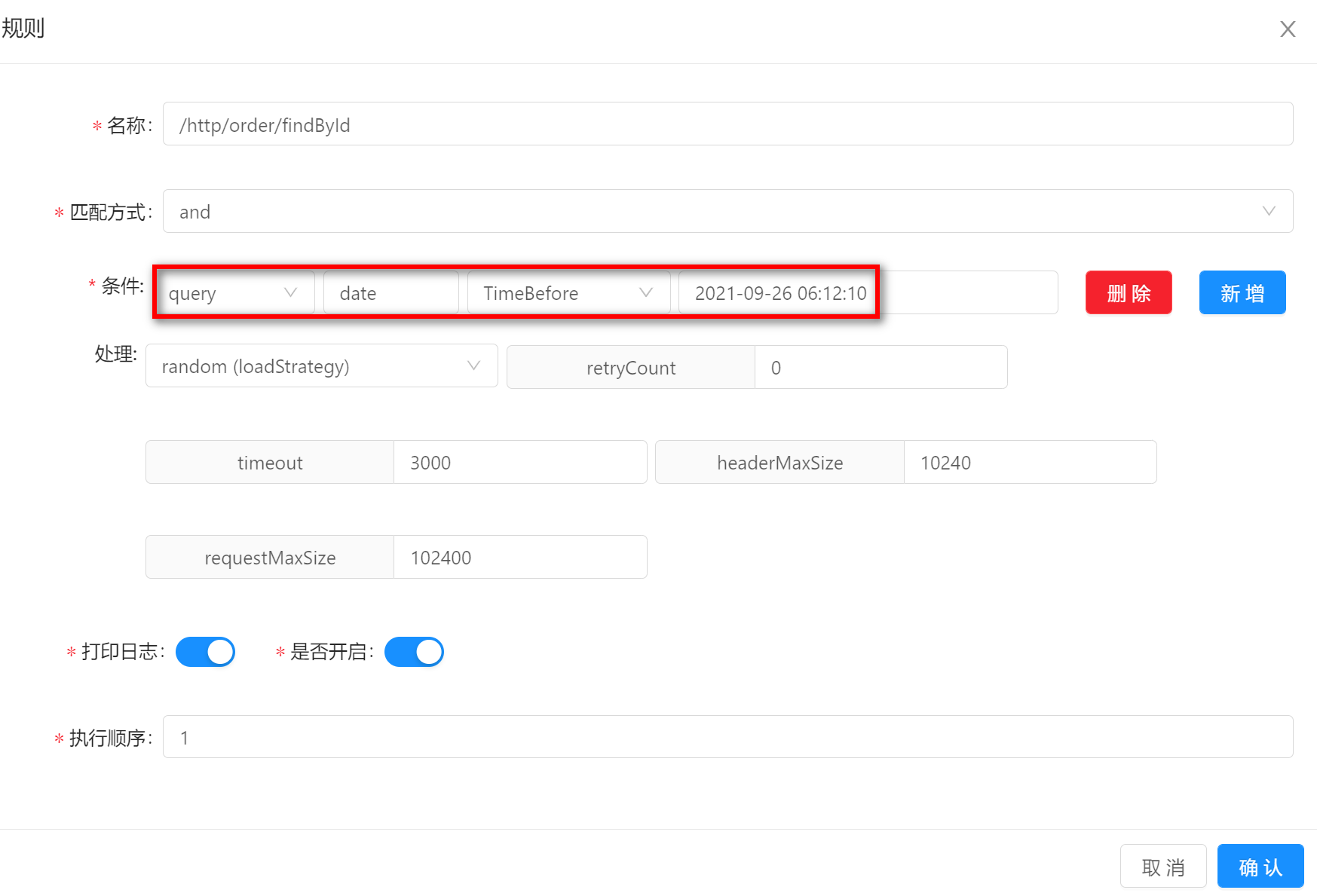
-
TimeAfterTimeAfter的方式表示请求时间在预设的条件时间之后才能匹配成功。假如你的规则条件设置如下:请求参数中包含date,并且date大于2021-09-26 06:12:10。那么请求/http/order/findById?id=100&date=2021-09-29 06:12:10就可以匹配上。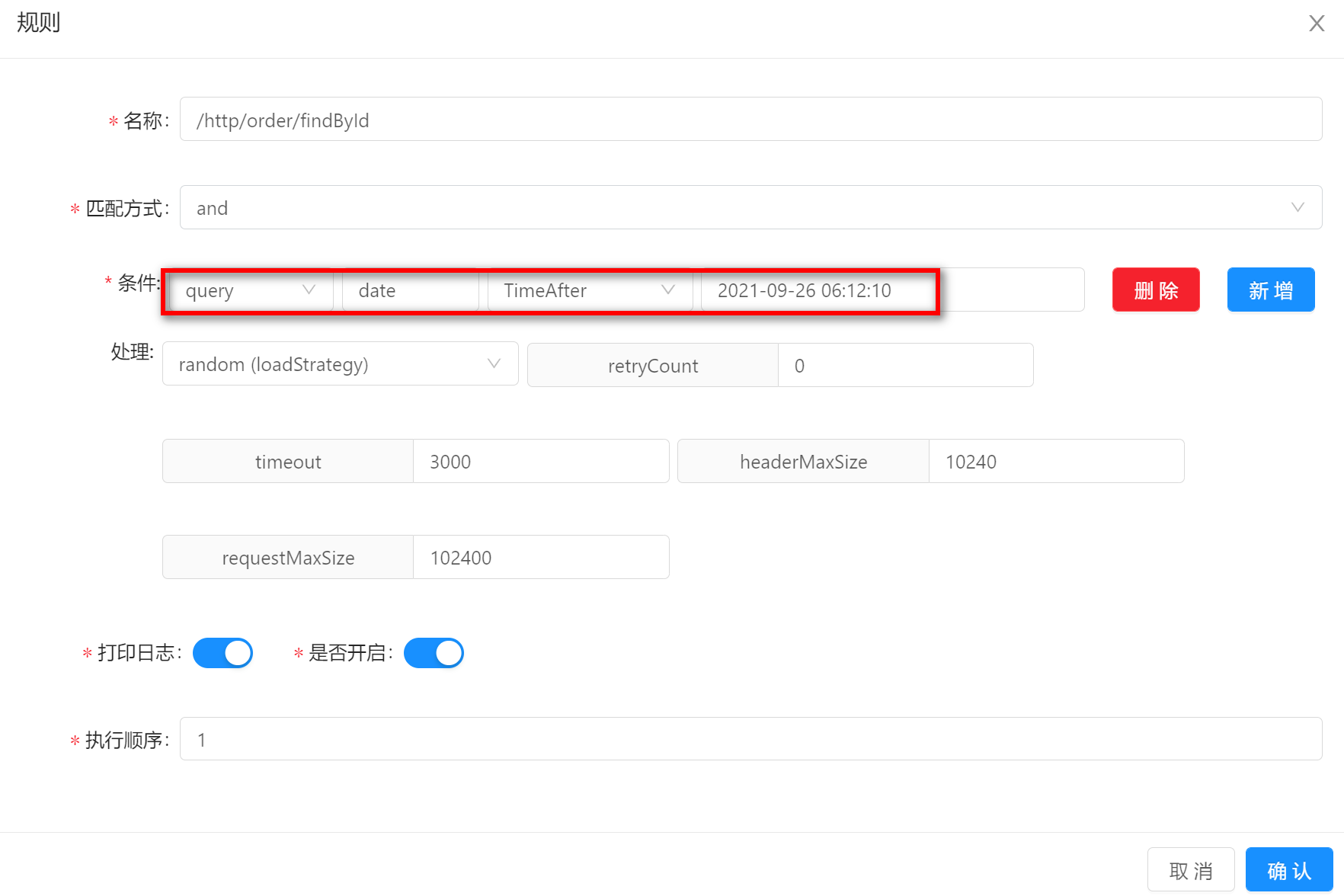
如果想更深入理解条件匹配策略,请阅读相关源码,包名是org.apache.shenyu.plugin.base.condition.judge:
| 匹配策略 | 源码类 |
|---|---|
match | MatchPredicateJudge |
= | EqualsPredicateJudge |
regex | RegexPredicateJudge |
contains | ContainsPredicateJudge |
SpEL | SpELPredicateJudge |
Groovy | GroovyPredicateJudge |
TimeBefore | TimerBeforePredicateJudge |
TimeAfter | TimerAfterPredicateJudge |
文中的示例是为了说明选择器和规则的使用,具体条件的设置需要根据实际情况选择。