RateLimiter SPI code analysis
Rate limiter is a very important integral of gateway application, to deal with high traffic. When the system is attacked abnormally by a large number of traffic gathered in a short time; When there are a large number of lower priority request need to be slow down or else it will effect your high priority transactions; Or sometimes your system can not afford the regular traffic; in these scenarios, we need to start rate limiter component to protect our system, through rejection, wait, load shedding,etc, limit the requests to an acceptable quantities, or only certain domains (or services) requests can get through.
Facing above scenarios, following need to be considered when designing the rate limiter component of an gateway.
- Supports a variety of rate limiter algorithms and easy to extends.
- Resilient resolvers which can distinguish traffic by different way, such as ip, url, even user group etc.
- High availability, can quickly get allow or reject result from rate limiter
- With fault tolerance against when rate limiter is down, the gateway can continue work.
This article will first introduce the overall architecture of the rate limiter module in Apache Shenyu, and then focus on the code analysis of rate limiter SPI.
This article based on
shenyu-2.4.0version of the source code analysis.
Overall design of RateLimiter
Spring WebFlux is reactive and non-blocking web framework, which can benefit throughput and make applications more resilient. The plugin of Apache Shenyu is based on WebFlux,its rate limiter component is implemented in ratelimiter-plugin. In rate limiter process, the commonly used algorithms are token bucket, leaky bucket, etc. To speed up concurrency performance, the counting and calculation logic is treated in Redis, and Java code is responsible for the transmission of parameters. When applying Redis, the Lua script can be resident memory, and be executed as a whole, so it is atomic. Let alone the reducing of network overhead. Redis commands abstraction and automatic serialization/deserialization with Redis store is provided in Spring Data Redis. Because of based on reactive framework, the Spring Redis Reactive is used in ratelimiter-plugin.
The class diagram of this plugin is as follows, highlighting two packages related to RateLimiter SPI: resolver 和algorithm.
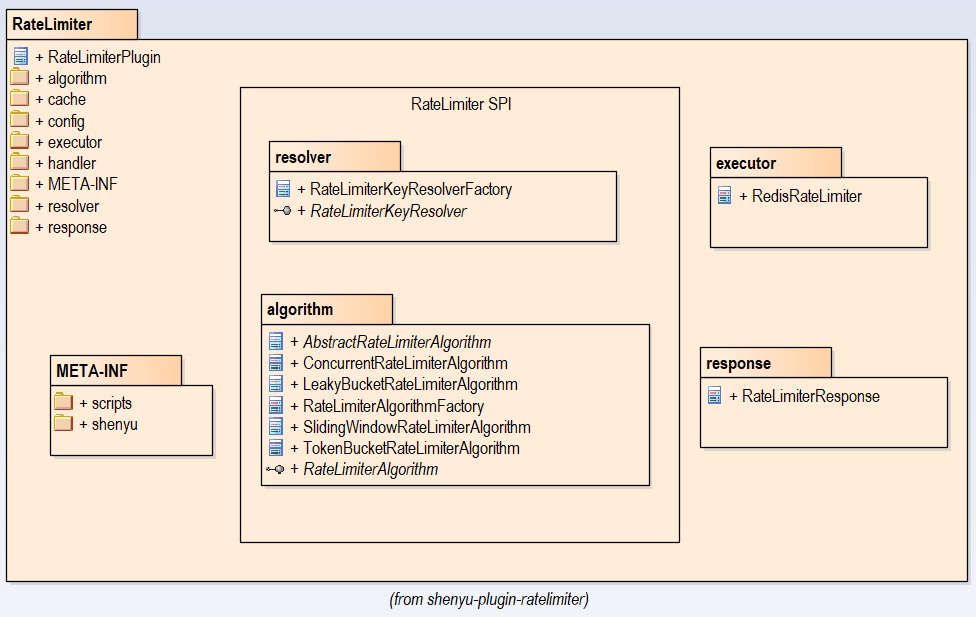
Design of RateLimiter SPI
High performance issue is achieved through the architecture of Spring data+ Redis+Lua , two SPI are supplied in ratelimiter-plugin for the extension of algorithm and key resolver。
- RateLimiterAlgorithm:used for algorithms expansion.
- RateLimiterKeyResolver: used for resolver expansion, to distinguish requests by various information, including ip, url, ect.
The profile of SPI is located at directory of SHENYU_DIRECTORY (default/META-INF/shenyu).
RateLimiterKeyResolver
Obtain the critical info of the request used for packet rate limiter,the interface of RateLimiterKeyResolver is follows:
@SPI
public interface RateLimiterKeyResolver {
/**
* get Key resolver's name.
*
* @return Key resolver's name
*/
String getKeyResolverName();
/**
* resolve.
*
* @param exchange exchange the current server exchange {@linkplain ServerWebExchange}
* @return rate limiter key
*/
String resolve(ServerWebExchange exchange);
}
@SPI registers the current interface as Apache Shenyu SPI. Method resolve(ServerWebExchange exchange) is used to provide the resolution way. Currently there are two key resolvers in RateLimiterKeyResolver SPI:WholeKeyResolve and RemoteAddrKeyResolver. The resolve method of RemoteAddrKeyResolveris as follows:
@Override
public String resolve(final ServerWebExchange exchange) {
return Objects.requireNonNull(exchange.getRequest().getRemoteAddress()).getAddress().getHostAddress();
}
Where the resolved key is ip of request. Based on SPI mechanism and its factory pattern, new resolver can be easily developed.
RateLimiterAlgorithm SPI
RateLimiterAlgorithm SPI is used to identify and define different rate limiter algorithms, following is the class diagram of this module.
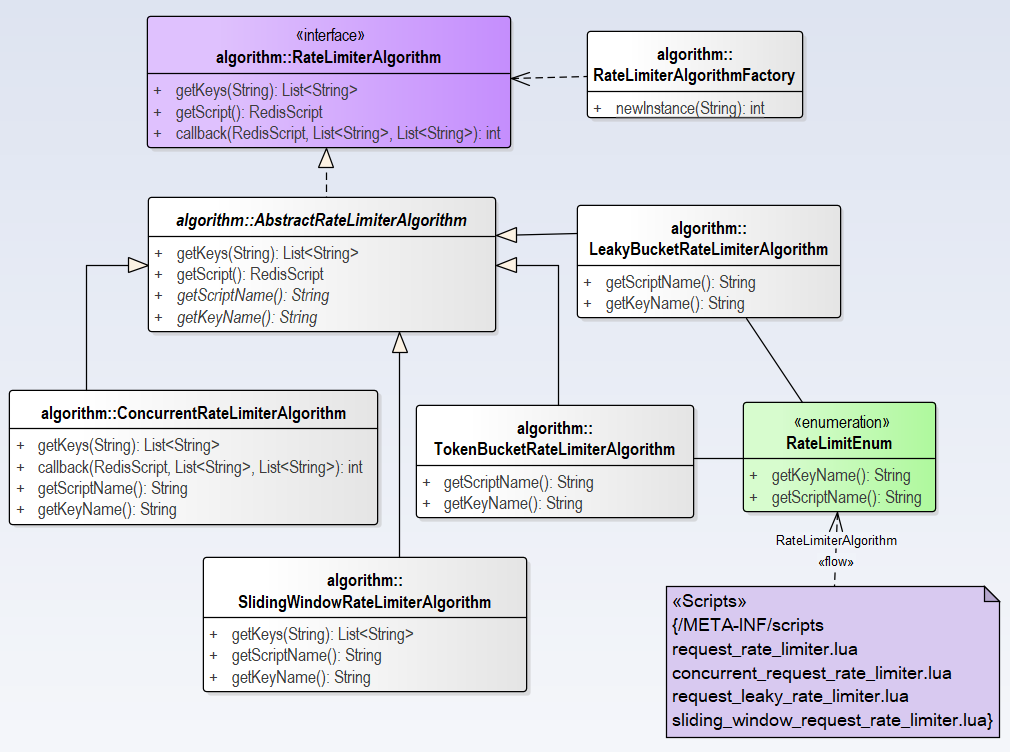
In this module, factory pattern is used , providing interface, abstract class and factory class, and four implementation classes. The lua script corresponding to the implementation class is enumerated in RateLimitEnum and located in /META-INF/scripts.
@SPI
public interface RateLimiterAlgorithm<T> {
RedisScript<T> getScript();
List<String> getKeys(String id);
/**
* Callback string.
*
* @param script the script
* @param keys the keys
* @param scriptArgs the script args
*/
default void callback(final RedisScript<?> script, final List<String> keys, final List<String> scriptArgs) {
}
}
@SPI registers the current interface as Apache Shenyu SPI. There are three methods:
getScript()returns aRedisScriptobject, which will be passed to Redis.getKeys(String id)returns a List contains with keys.callback()the callback function which will be executed asynchronously later on, and default is an empty method.
AbstractRateLimiterAlgorithm
The template method is implemented in this abstract class, and the reified generics used is List<Long>. Two abstract methods getScriptName() and getKeyName() are left for the implementation class. Following is the code to load lua script.
public RedisScript<List<Long>> getScript() {
if (!this.initialized.get()) {
DefaultRedisScript redisScript = new DefaultRedisScript<>();
String scriptPath = "/META-INF/scripts/" + getScriptName();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(scriptPath)));
redisScript.setResultType(List.class);
this.script = redisScript;
initialized.compareAndSet(false, true);
return redisScript;
}
return script;
}
initialized is an AtomicBoolean type variable used to indicate whether the lua script is loaded. If has not been loaded, the system will read specified scripts form META-INF/scripts; After reading, specify the result with List type, and set initialized=true, then returning RedisScriptobject.
The code of getKeys() in AbstractRateLimiterAlgorithm is as follows:
@Override
public List<String> getKeys(final String id) {
String prefix = getKeyName() + ".{" + id;
String tokenKey = prefix + "}.tokens";
String timestampKey = prefix + "}.timestamp";
return Arrays.asList(tokenKey, timestampKey);
}
Two strings are generated in this template method, where the tokenKey will work as Key to a Sorted map in Redis.
We can observe from above class diagram that ConcurrentRateLimiterAlgorithm and SlidingWindowRateLimiterAlgorithm override getKeys(String id) method but another two implementation classes not, and use template method in AbstractRateLimiterAlgorithm. Only in ConcurrentRateLimiterAlgorithm has override callback() method, the others not. We will do further analysis in the following.
RateLimiterAlgorithmFactory
The method getsRateLimiterAlgorithm instance by name in RateLimiterAlgorithmFactory is as follows:
public static RateLimiterAlgorithm<?> newInstance(final String name) {
return Optional.ofNullable(ExtensionLoader.getExtensionLoader(RateLimiterAlgorithm.class).getJoin(name)).orElse(new TokenBucketRateLimiterAlgorithm());
}
ExtensionLoader of SPI is responsible for loading SPI classes by "name", if cannot find the specified algorithm class, it will return TokenBucketRateLimiterAlgorithm by default.
Data access with Redis
Above detailed the extension interface in RateLimiter SPI. In Apache Shenyu, we use ReactiveRedisTemplate to perform Redis processing reactively, which is implemented inisAllowed() method of RedisRateLimiter class.
public Mono<RateLimiterResponse> isAllowed(final String id, final RateLimiterHandle limiterHandle) {
// get parameters that will pass to redis from RateLimiterHandle Object
double replenishRate = limiterHandle.getReplenishRate();
double burstCapacity = limiterHandle.getBurstCapacity();
double requestCount = limiterHandle.getRequestCount();
// get the current used RateLimiterAlgorithm
RateLimiterAlgorithm<?> rateLimiterAlgorithm = RateLimiterAlgorithmFactory.newInstance(limiterHandle.getAlgorithmName());
........
Flux<List<Long>> resultFlux = Singleton.INST.get(ReactiveRedisTemplate.class).execute(script, keys, scriptArgs);
return resultFlux.onErrorResume(throwable -> Flux.just(Arrays.asList(1L, -1L)))
.reduce(new ArrayList<Long>(), (longs, l) -> {
longs.addAll(l);
return longs;
}).map(results -> {
boolean allowed = results.get(0) == 1L;
Long tokensLeft = results.get(1);
return new RateLimiterResponse(allowed, tokensLeft);
})
.doOnError(throwable -> log.error("Error occurred while judging if user is allowed by RedisRateLimiter:{}", throwable.getMessage()))
.doFinally(signalType -> rateLimiterAlgorithm.callback(script, keys, scriptArgs));
}
The POJO class RateLimiterHandle wraps the parameters needed in rate limiter, they are algorithName, replenishRate, burstCapacity, requestCount, etc. First, gets the parameters that need to be passed into Redis from RateLimiterHandle class. Then obtain the current implementation class from RateLimiterAlgorithmFactory.
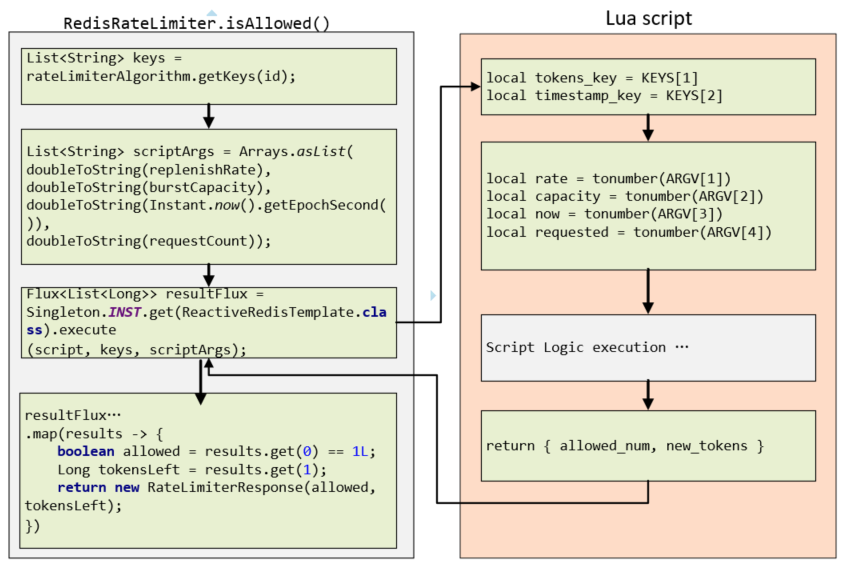
For convenience, we give an flow image to show the parameters I/O and execution procedure in Java and Redis respectively. On the left is the second half of isAllowed() , and on the right is the processing of Lua script.
Following is the execution process of the JAVA code.
-
Get two keys value in
List<String>type from thegetKeys()method, the first element will map to a sorted set in Redis. -
Set four parameters,
replenishRate,burstCapacity,timestamp(EpochSecond) andrequestcount. -
Calling
ReactiveRedisTemplatewith the scripts, keys and parameters, the return aFlux<List<Long>> -
The return value is converted from
Flux<ArrayList<Long>>toMono<ArrayList<Long>>the throughreduce()ofFlux,and then transform it toMono<RateLimiterResponse>viamap()function. Returned two data, one isallowed(1-allow, 0- not allowed), the other istokensLeft, the number of available remaining request. -
As for the fault tolerance, due to using of reactor non-blocking model, when an error occurs, the fallback function
onErrorResume()will be executed and a new stream(1L, -1L)will generated byFlux.just,which means allow the request getting through, and log the error on the side. -
After that, performs the
doFinally()method, that is to execute the callback() method of the implementation class.
Four rate limiter algorithms
From above we know that how the java code works with Redis in the gateway. In this chapter we briefly analysis some code of the four rate limiter algorithms, to understand how to develop the interface of RateLimiter SPI and work efficiently with Redis.
Four rate limiter algorithms are supplied in Apache Shenyu Ratelimit SPI:
| Algorithm name | Java class | Lua script file |
|---|---|---|
| Request rate limiter | TokenBucketRateLimiterAlgorithm | request_rate_limiter.lua |
| Slide window rate limiter | SlidingWindowRateLimiterAlgorithm | liding_window_request_rate_limiter.lua |
| Concurrent rate limiter | ConcurrentRateLimiterAlgorithm | concurrent_request_rate_limiter.lua |
| Leaky bucket algorithm | LeakyBucketRateLimiterAlgorithm | request_leaky_rate_limiter.lua |
- Token bucket rate limiter: Limiting the traffic according to the number of requests. Assuming that N requests can be passed per second, when requests exceeding N will be rejected. In implementing of the algorithm, the requests will be grouped by bucket, the tokens will be generated at an evenly rate. If the number of requests is less than the tokens in the bucket, then it is allowed to pass. The time window is 2* capacity/rate.
- Slide window rate limiter: Different from token bucket algorithm, its window size is smaller than that of token bucket rate limiter, which is a capacity/rate. And move backward one time window at a time. Other rate limiter principles are similar to token bucket.
- Concurrent rate limiter: Strictly limit the concurrent requests to N. Each time when there is a new request, it will check whether the number of concurrent requests is greater than N. If it is less than
N, it is allowed to pass through, and the count is increased by 1. When the requests call ends, the signal is released (count minus 1). - Leaky bucket rate limiter: In contrast with token bucket algorithm, the leaky bucket algorithm can help to smooths the burst of requests and only allows a pre-defined N number of requests. This limiter can force the output flow at a constant rate of N. It is based on a leaky bucket model, the leaky water quantity is time interval*rate. if the leaky water quantity is greater than the number of has used (represented by
key_bucket_count), then clear the bucket, that is, set thekey_bucket_countto 0. Otherwise, setkey_bucket_countminus the leaky water quantity. If the number (requests +key_bucket_count) is less than the capacity, then allow the requests passing through.
Let's understand the functionality of callback() by reading concurrent rate limiter code, and understand the usage of getKeys() through reading the Lua script of token rate limiter and slide window rate limiter.
callback() used in Concurrent requests limiter
The getKeys() method of ConcurrentRateLimiterAlgorithm overrides the template method in AbstractRateLimiterAlgorithm :
@Override
public List<String> getKeys(final String id) {
String tokenKey = getKeyName() + ".{" + id + "}.tokens";
String requestKey = UUIDUtils.getInstance().generateShortUuid();
return Arrays.asList(tokenKey, requestKey);
}
The second element, requestKey is a long type and non-duplicate value (generated by a distributed ID generator,it is incremented and smaller than the current time Epochsecond value). The corresponding Lua script in concurrent_request_rate_limiter.lua:
local key = KEYS[1]
local capacity = tonumber(ARGV[2])
local timestamp = tonumber(ARGV[3])
local id = KEYS[2]
Here id is requestKey generated by getKeys() method, it is an uuid(unique value). Subsequent process is as follows:
local count = redis.call("zcard", key)
local allowed = 0
if count < capacity then
redis.call("zadd", key, timestamp, id)
allowed = 1
count = count + 1
end
return { allowed, count }
First, using zcard command to obtain the cardinality of the sorted set, and set count equals the cardinality , if the cardinality is less than the capacity, we will add a new member id (it is an uuid) to the sorted set, with the score of current time(in seconds) . then count =count+1, the cardinality is also incremented by 1 in reality.
All of the code above is executed in Redis as an atomic transaction. If there are a large number of concurrent requests from the same key( such as ip) , the cardinality of the sorted set of this key will increasing sharply, when then capacity limit is exceeded, the service will be denied, that is allowed =0。
In concurrent requests limiter, It is required to release the semaphore when the request is completed. However, it is not included in Lua script.
Let's see the callback function of ConcurrentRateLimiterAlgorithm:
@Override
@SuppressWarnings("unchecked")
public void callback(final RedisScript<?> script, final List<String> keys, final List<String> scriptArgs) {
Singleton.INST.get(ReactiveRedisTemplate.class).opsForZSet().remove(keys.get(0), keys.get(1)).subscribe();
}
Here gives asynchronous subscription, using ReactiveRedisTemplate to delete the elements (key,id) in Redis store. That is once the request operation ends, the semaphore will be released. This remove operation cannot be executed in Lua script. This is just what design intention of callback in RateLimiterAlgorithm SPI .
getKeys() used in token bucket rate limiter
Following is the corresponding Lua code:
local tokens_key = KEYS[1]
local timestamp_key = KEYS[2]
Here we omit the code that get the parameters of rate ,capacity, etc.
local fill_time = capacity/rate
local ttl = math.floor(fill_time*2)
The window size variable(ttl) is approximately two times of capacity/rate.
local last_tokens = tonumber(redis.call("get", tokens_key))
if last_tokens == nil then
last_tokens = capacity
end
Get last_tokens from the sorted set, if it not exist, then last_tokens equals capacity.
local last_refreshed = tonumber(redis.call("get", timestamp_key))
if last_refreshed == nil then
last_refreshed = 0
end
Get the last refreshed time by the key =timestamp_key from the sorted set, and default 0.
local delta = math.max(0, now-last_refreshed)
local filled_tokens = math.min(capacity, last_tokens+(delta*rate))
local allowed = filled_tokens >= requested
local allowed_num = 0
if allowed then
new_tokens = filled_tokens - requested
allowed_num = 1
end
The filled_tokens is produced evenly by time interval * rate,if the number of tokens greater than requests, then allowed=1, and update new_tokens.
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
return { allowed_num, new_tokens }
Here now is current time parameters passed in, set tokens_key to hold the string new_tokens and settokens_key to timeout after ttl of seconds. Set timestamp_key to hold the string value now, and expires after ttl seconds.
getKeys() used in sliding window rate limiter
The getKeys() in SlidingWindowRateLimiterAlgorithm also overrides the parent class, and the code is consistent with the method in ConcurrentRateLimiterAlgorithm
Following is the Lua code of slide window rate limiter, the receiving of other parameters is omitted.
local timestamp_key = KEYS[2]
......
local window_size = tonumber(capacity / rate)
local window_time = 1
Here set the window_size to capacity/rate.
local last_requested = 0
local exists_key = redis.call('exists', tokens_key)
if (exists_key == 1) then
last_requested = redis.call('zcard', tokens_key)
end
Obtain the cardinality(last_requested) of the tokens_key in the sorted set.
local remain_request = capacity - last_requested
local allowed_num = 0
if (last_requested < capacity) then
allowed_num = 1
redis.call('zadd', tokens_key, now, timestamp_key)
end
Calculate remaining available remain_request equals capacity minus last_requested . If last_requested less than capacity ,then allow current requests passing through,add element in the sorted set with (key=timestamp_key, value=now) .
redis.call('zremrangebyscore', tokens_key, 0, now - window_size / window_time)
redis.call('expire', tokens_key, window_size)
return { allowed_num, remain_request }
Previously has set window_time=1, using zremrangebyscore command of Redis to remove all the elements in the sorted set stored at tokens_key with a score in [0,now - window_size / window_time] , that is, move the window a window size. Set the expire time of tokens_key to window_size.
In the template method getKeys(final String id) of AbstractRateLimiterAlgorithm,the second key ( represented y secondKey) is a fixed string which concat the input parameter{id}. As we can see from the above three algorithm codes, in the token bucket algorithm, secondKey will be updated to the latest time in the Lua code, so it doesn't matter what value is passed in. In the concurrent rate limiter, secondKey will be used as the key to remove Redis data in the java callback method. In the sliding window algorithm, the secondKey will be added to the sorted set as the key of a new element, and will be removed during window sliding.
That's all, when in a new rate limiter algorithm, the getKeys(final String id)method should be carefully designed according to the logic of the algorithm.
How to use RateLimiter SPI
The three parameters in doExecute() method of RateLimiter plugin, exchange is an web request, chain is the execution chain of the plugins,selector is the selection parameters,rule is the policies or rules of rate limiter setting in the system.
protected Mono<Void> doExecute(final ServerWebExchange exchange, final ShenyuPluginChain chain, final SelectorData selector, final RuleData rule) {
//get the `RateLimiterHandle` parameters from cache
RateLimiterHandle limiterHandle = RatelimiterRuleHandleCache.getInstance()
.obtainHandle(CacheKeyUtils.INST.getKey(rule));
//find the resolver name
String resolverKey = Optional.ofNullable(limiterHandle.getKeyResolverName())
.flatMap(name -> Optional.of("-" + RateLimiterKeyResolverFactory.newInstance(name).resolve(exchange)))
.orElse("");
return redisRateLimiter.isAllowed(rule.getId() + resolverKey, limiterHandle)
.flatMap(response -> {
if (!response.isAllowed()) {
exchange.getResponse().setStatusCode(HttpStatus.TOO_MANY_REQUESTS);
Object error = ShenyuResultWrap.error(ShenyuResultEnum.TOO_MANY_REQUESTS.getCode(), ShenyuResultEnum.TOO_MANY_REQUESTS.getMsg(), null);
return WebFluxResultUtils.result(exchange, error);
}
return chain.execute(exchange);
});
}
-
Firstly get the
RateLimiterHandleparameters from cache. -
Obtains the corresponding Key resolver by
RateLimiterHandleinstance. -
Reactively executes
isAllowed()method ofRedisRateLimiter. -
If not allowed, error handling is performed.
-
If the request is allowed, dispatch it to the next process of execution chain.
Summary
RateLimiter plugin is based on Spring WebFlux,and with Apache Shen SPI, with Redis and Lua script to responsible for the critical algorithm and logic process, make it with characteristics of high concurrency and elastic. As for the RateLimiter SPI.
RateLimiterSPIprovides twoSPIinterface, with interface oriented design and various design patterns, it's easy to develop new rate limiter algorithm and key resolver rule.RateLimiterAlgorithmSPIsupplies four rate limiter algorithms, token bucket,concurrency rate limiter, leaky bucket and sliding window rate limiter. When designing rate limiter algorithm, the KEY generation need to be carefully designed according to the algorithm characteristic. Using Lua script to realize the logic of the algorithm, and design callback() method for asynchronous processing when needed.- Reactive programming, simple and efficient implementation.